
将时间还原到2019年6月之前,扫描器的世界大多还停留在AWVS这样的主动扫描器,被动扫描曾被提出作为浏览器插件火热过一段时间,可惜效率太低等多种问题束缚着它的发展。随着Xray的发布,一款免费好用的被动扫描器从很多方面都带火了自动化漏洞扫描的风潮。
其中有的人将Xray挂在自己的常用浏览器上以图在使用的过程中捡漏,有的人只在日站的时候挂上以图意外之喜,也有人直接操起自己尘封已久的爬虫配合xray大范围的扫描以图捡个痛快。可以说配合xray日站在当时已经成了一股风潮。
市面上比较常见的组合crawlergo+xray中的crawlergo也正是在这种背景下被开放出来。
但可惜的是,建立在自动化漏洞挖掘的基础上,当人们使用相同的工具,而我们又没办法自定义修改,是否能发现漏洞变成了是否能发现更多的资产的比拼。建立在这样的背景下,我决定自己发起了一个开源的爬虫项目,这就是LSpider诞生的背景。
LSpider作为星链计划的一员,已经开源,工具可能并不算成熟,但持续的维护以及更新是星链计划的精神~
LSpider想要做到什么?
在发起一个项目之初,我们往往忘记自己到底为什么开始,为什么要写这个项目,重复造轮子,以及闭门造车从来都不是我们应该去做的事。
而LSpider发起的初衷,就是为被动扫描器量身打造一款爬虫。
而建立在这个初衷的基础上,我决定放弃传统爬虫的那些多余的功能。
这是一个简单的传统爬虫结构,他的特点是爬虫一般与被动扫描器分离,将结果输入到扫描器中。
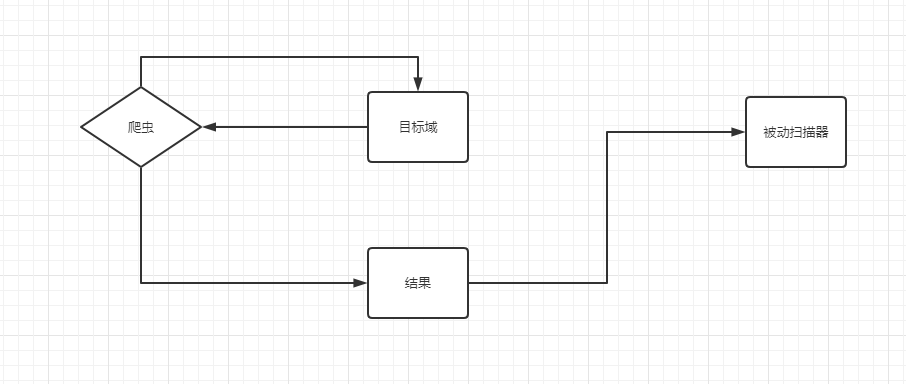
将被动扫描器直接代理到爬虫上
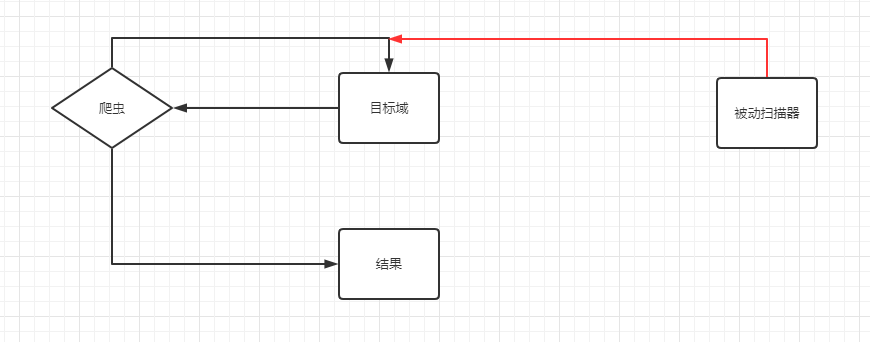
这样一来,爬虫的主要目标转变为了,尽可能的触发更多的请求、事件、流量。
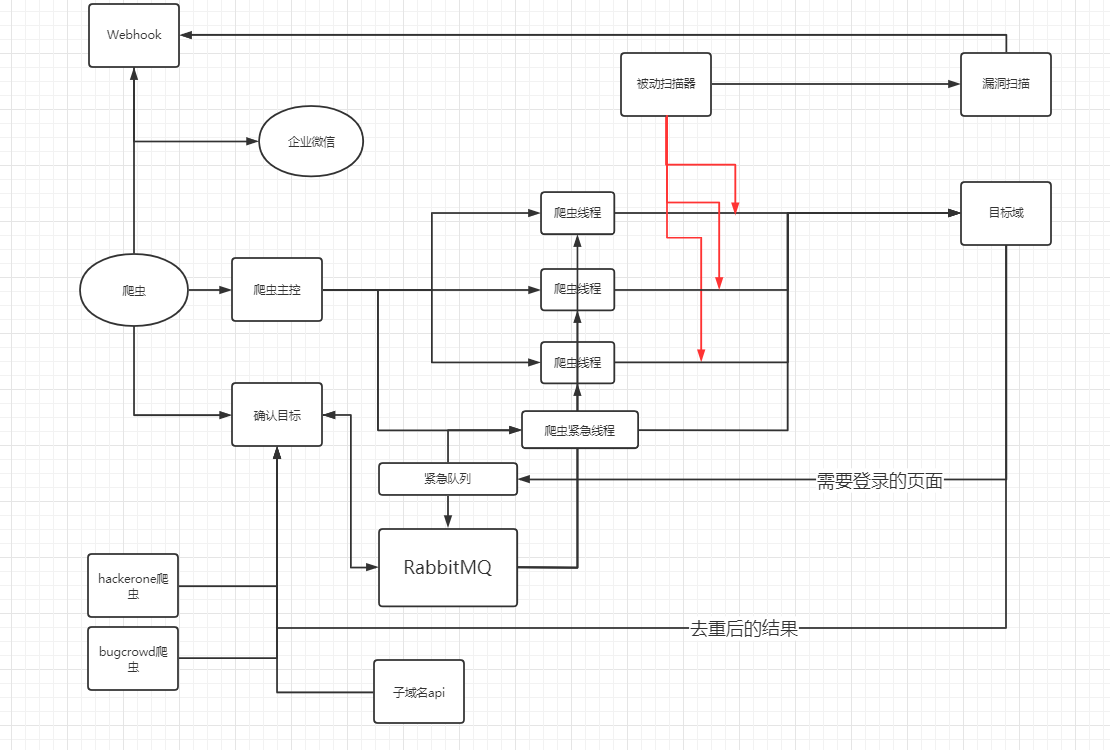
建立在这个大基础上,我们得到了现在的架构:
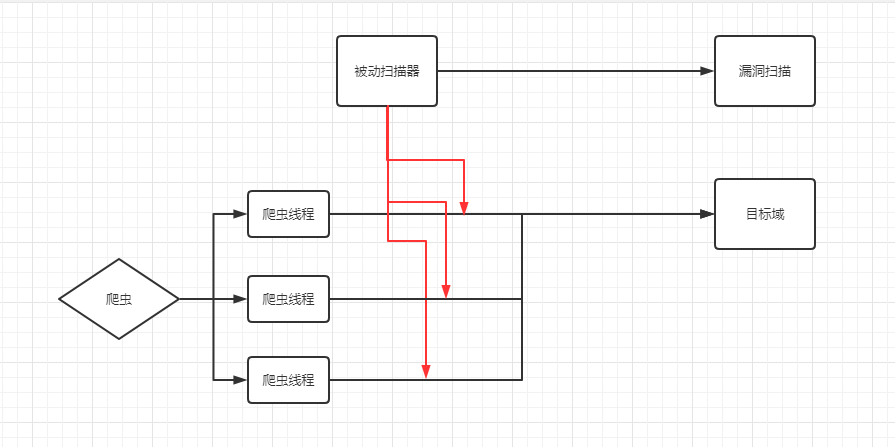
由主控分配爬虫线程,扫描目标域,并尽可能的触发更多的请求、事件、流量。将被动扫描器通过代理的方式挂在爬虫下并独立的完成漏洞扫描部分。
除了为被动扫描器服务以外,还有什么是在项目发起时的初衷呢?
我的答案是,这个爬虫+被动扫描器的目的是,能让我不投入过多精力的基础上,挖洞搞钱!!!
不在乎扫到什么漏洞,不在乎扫到什么厂商,只求最大限度的扫描目标相关所有站、所有域名、所有目标。
为了实现这个目标,我在爬虫中内置了查询子域名的api,内置了hackerone、bugcrowd目标爬虫,在设计之初还添加了定时扫描功能。
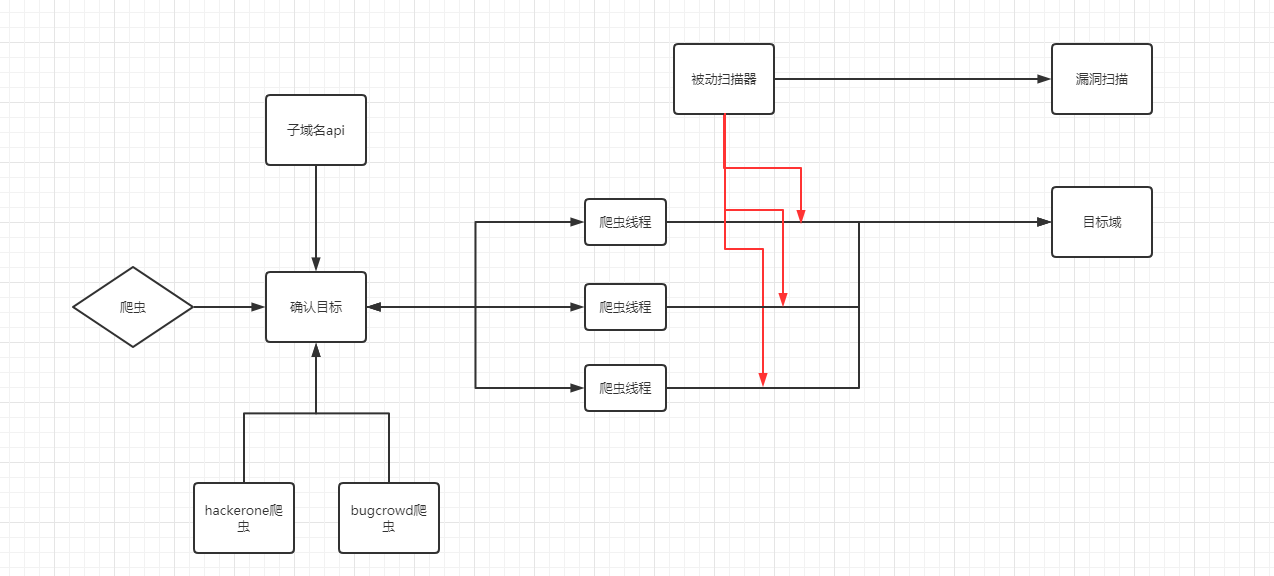
到目前为止,我们设计了一个自动化无限制扫描目标,且为被动扫描器而存在的爬虫架构。
下面我们一起完成这个项目。
爬虫基础
首先爬虫部分,为了实现最大程度上触发更多的请求、事件、流量,我们有且只有唯一的选择为Chrome Headless.
配置Chrome Headless
这里我选择了selenium来操作Chrome WebDriver。值得注意的是几个比较重要的配置。
1 | self.chrome_options.add_argument('--headless') |
除了设置headless模式以外,还关闭了一些无意义的设置。
1 | if os.name == 'nt': |
设置好文件下载的目录,如果没设置的话会自动下载大量的文件在当前文件夹。
1 | desired_capabilities = self.chrome_options.to_capabilities() |
通过org.openqa.selenium.Proxy来设置浏览器代理,算是比较稳定的方式。
1 | self.driver.set_page_load_timeout(15) |
这两个配置可以设置好页面加载的超时时间,在大量的扫描任务中,这也是必要的。
除了基础配置以外,有个值得注意的点是:
你必须在访问页面之后才可以设置cookie,且cookie只能设置当前域,一旦涉及到跳转,这种cookie设置方式就不会生效。
1 | self.origin_url = url |
模拟点击以及智能填充
在配置好chrome headless之后,为了模拟人类的使用,我抛弃了传统爬虫常用的拦截、hook等获取请求并记录的方式,转而将重心放在模拟点击以及智能填充上。
模拟点击
这里拿a标签举例子
1 | links = self.driver.find_elements_by_xpath('//a') |
当获取到对应标签时,首先将对应的标签属性taget置空(不打开新的标签页),然后模拟点击按钮,之后检查是否发生跳转,并返回原页面。
同样的逻辑被复用在了button,input@type=submit和拥有onclick事件标签上,值得注意的是。button这样的标签还加入模拟鼠标移动的操作。
1 | if submit_button.is_displayed() and submit_button.is_enabled(): |
智能表单填充
这里我把智能表单填充分为两部分,首先我们需要判断当前页面是否存在一个登录框,这意味着当前页面并没有登录(如果登录状态,一般登录框会消失)。
这里把可能出现登录框的页面分为4种
1 | form -> 文本中出现login、登录、sign等 |
当当前页面满足上述任一条件时,则会记录下来到相应的位置(后续会提到)
然后会尝试填充页面的所有框框。
1 | inputs = self.driver.find_elements_by_xpath("//input") |
首先去掉表单框上的所有CSS,并将鼠标放置到对应的位置。
紧接着通过判断表单的key值,满足条件的对应填入部分预设的用户名,密码,邮箱,地址,手机号,并勾选所有的单选多选框,其余输入框则生成随机字符串填入。
结果去重
到目前为止,我们至少触发了属于页面中大量的请求,接下来我们就遇到了另一个问题,如何对流量去重?
除了尽可能的触发请求以外,爬虫也并不是单一执行流程的,每个爬虫需要不断地从某个主控(RabbitMQ)获取新的目标,而爬虫也需要不断地返回目标,但我们就需要去重逻辑来完成新目标的处理,这样可以最大限度的减少无意义的请求。
这里我使用了一套比较简单的url泛化逻辑来做去重。首先我将获取的返回和历史记录中相同域的url提取出来。
1 | BLACK_DOMAIN_NAME_LIST = ['docs', 'image', 'static', 'blogs'] |
首先,如果域名中存在上面4个黑名单词语,则只接受200条不重复请求。
然后将,所有的路径泛化,按照/做分割,用A来代表纯数字段,用B来代表字母混合段。
1 | https://lorexxar.cn/2020/10/30/whitebox-2/ |
如果历史记录已经存在flag为AAAB的链接,则会进入更深层次的判断。
紧接着会提取比较的两个链接的B段内容。
首先判断当前路径下是否附和一些特殊路径,如
1 | BLACK_PATH_NAME = ['static', 'upload', 'docs', 'js', 'css', 'font', 'image'] |
如果满足,那么直接限制该路径下只收录100个链接,如果不满足,那么会提出两个url的B段进行比较。也就是whitebox-2,如果不同,则判定为拥有1个不同点。
且如果当前B段为路径的最后一部分,举例子为
1 | https://lorexxar.cn/2020/10/30/whitebox-2/a.php |
这里的a.php就是路径的最后一部分,如果两个链接的最后一部分不为静态资源,则会被直接认定为不同请求。
如果最后一部分相同,且不同点不超过1个,那么会进入参数判断。
这里我们直接简单粗暴的获取所有请求的key,如果两个请求都拥有相同的参数列表,则两个链接为不同请求。(会剔除没有value的参数,如?20210127这类时间戳)
直接经过所有的判断,该链接才会被加入到新的目标列表当中,等待下一次被塞入任务队列中。
完成整体架构
在经历了爬虫基础架构以及模拟点击、智能填充之后,我们顺利的完成了爬虫最基础的部分,接下来我们需要完成蓝框部分的逻辑。
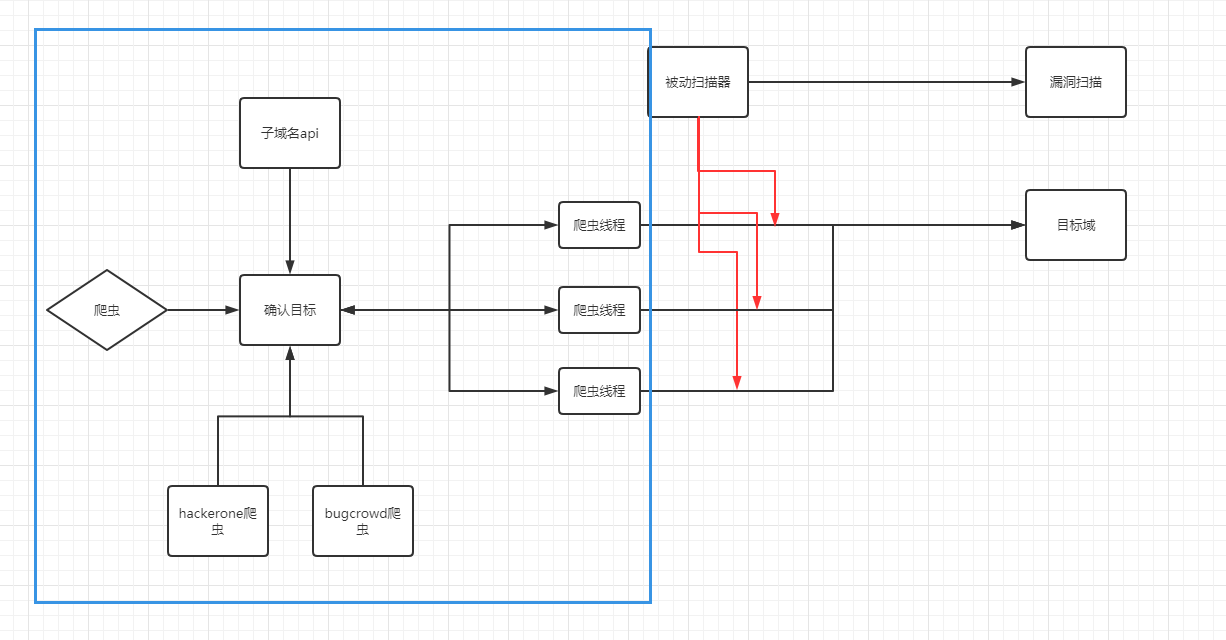
对于一个扫描器来说,最重要的就是稳定以及速度
在设计之初,我本来觉得LSpider是个私人使用的小工具,于是就简单的使用队列+多线程来做爬虫的调度,但是在使用的过程中,我逐渐发现Python队列会简单的将数据存在内存中,而Chrome Headless会消耗大量的机器资源,如果内存不够,就会陷入爬虫端越来越慢,内存却越来越大的境地,于是我将架构换成了用RabbitMQ做任务管理。
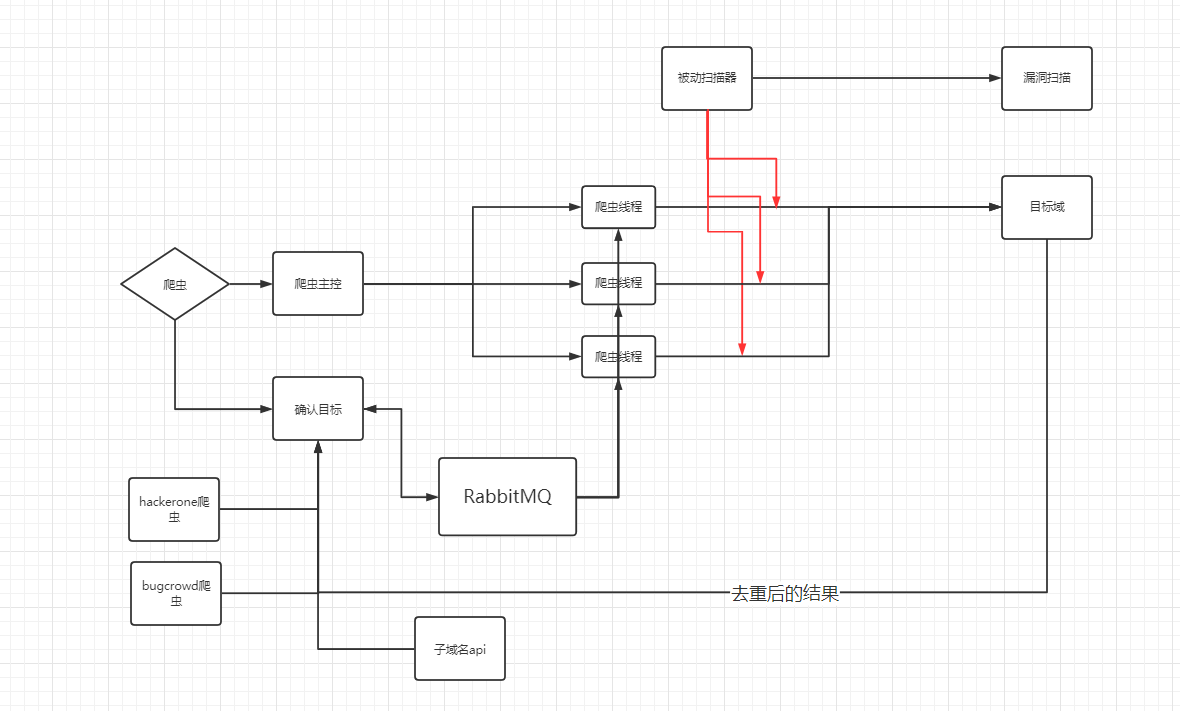
这样一来,我们爬虫主控与数据处理的部分分离开来,两个部分都只需要负责自己的任务即可。爬虫线程可以直接监听RabbitMQ来获取任务。
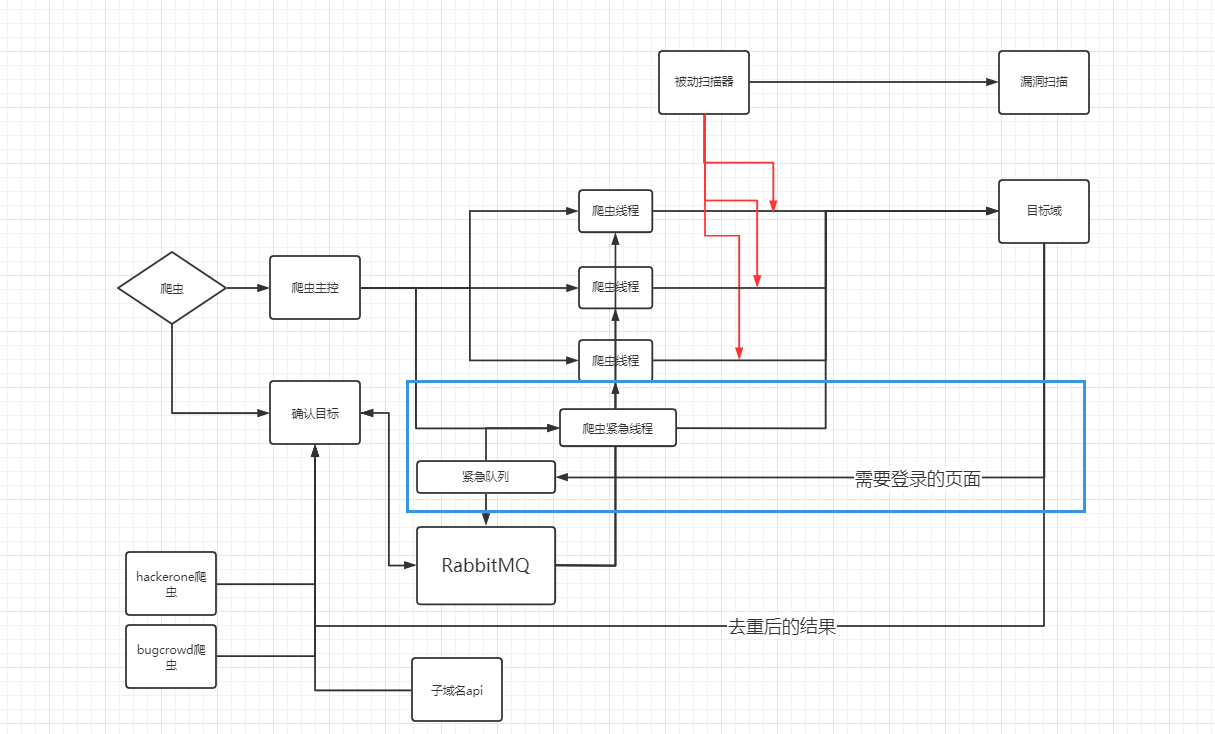
加入登录页面检查以及紧急队列
在LSpider的使用过程中,由于我设计了发散式的扫描方案。针对A域名的扫描往往会蔓延到上百个新的域名(包括子域名),其中单靠添加任务时候添加的鉴权验证远远不够,再加上我逐渐发现这种发散式的扫描方案,很容易发现特别多目标资产,比如某OA、某邮件系统等。
于是我添加了登录页面的检查(前文提到),一旦识别到登陆页面,我将会保留当前页面的url以及title,并进行一次指纹识别,并将相应的结果保存下来。
当我们收到了需要登录页面的推送时,我们又遇到了新的问题,假设任务列表已经陆陆续续储存了几十万条请求,当我们完成了账号的注册和登录,并将cookie设置好后,这个任务被重新加入到队列的尾,等到任务再次跑到时,可能cookie已经失效了,怎么解决呢?
这里我尝试引用了紧急队列来作为解决方案。这里涉及到一个概念是RabbitMQ的消息优先级,队列可以设置最大优先级,消息可以设置自己的优先级。在从队列中获取数据的时候,RabbitMQ会优先取出优先级更高的消息。
这里我们直接新建一个单独的线程和队列来轮询检查登录状态。一旦满足登录成功,那么该任务就会以高优先级的权重被加入到主队列中。通过这种方式来实现紧急任务的管理。
通过webhook+企业微信应用管理任务进度
当我们完成了整个工具的主线架构之后,就需要完善一些无关竟要但是又对体验帮助很大的小功能了。
当扫描器扫描到漏洞的时候,我需要第一时间获得消息。当爬虫发现需要登录的站点时,我需要第一时间去加上鉴权信息,说不定还刚好是我有的0day资产,我也必须第一时间拿到结果。
为了实现这个需求,我必须将工具和”宇宙第一通讯工具”联动起来,这里我们直接通过webhook和企业微信的小应用联动起来。
这里直接用django起一个webhook接口,配合一些简单的解析对接到被动扫描器上。然后将结果通过webchatpy推送到企业微信的应用上,效果是这样的:
登录推送: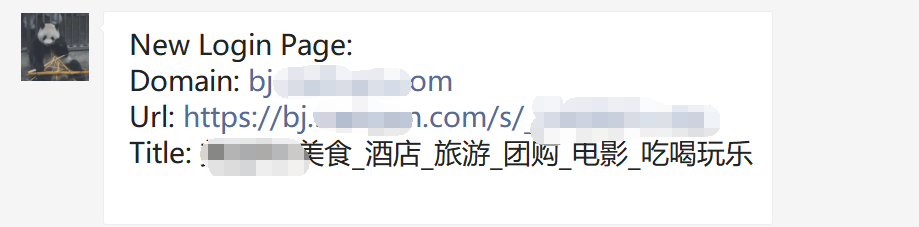
每时推送+漏洞推送
在经历了前面多步的完善,我们终于完成了LSpider,他的架构也变成了这样:
写在LSpider之后
LSpider是在疫情期间发起的项目,选择Django+python是因为这个项目最初更像是一个小玩具,再加上爬虫本来就是应该长期跑在服务端的工具,所以没太考虑就写起来用起来了。
幸运的是,在整个工具实现的过程中,我陆陆续续挖掘了超过150+个漏洞,也完成了设计之初对工具的预想,实现了长时间自动化挖掘的目的。但也可惜的是,大多数的漏洞都没有找到对应的src,于是也就丢在一边不管了。在优化的过程中,也越来越感受到局限。
在项目发起的时候,心里觉得项目最麻烦的肯定是去重、爬虫部分,但没想到在边写边用边修的过程中就零零散散的度过了1年,到项目的后期之后,越来越发现由于Xray本身并不开源,再加上Xray这个工具重心就不在对外漏洞扫描上。越来越多的问题涌现出来。
且不提许多自己的漏扫想法没办法优化,光是xray本身就存在诸多无意义的扫描(比如服务器配置错误等,对于挖洞来说毫无意义)。尤其是在阅读到许多曝光的漏洞信息之后,80%的时间你都没办法做任何事。
也正是在这样的背景下,我们意识到哪怕是背靠一个优秀的被动扫描器,我们也没办法将爬虫和被动扫描器拆分开来。于是我们又发起了第二个项目HeLuo,如果有机会的话,可能还有机会开源出来~
希望越来越多的朋友愿意试用LSpider,就像星链计划的初衷一般,开源项目的意义便是参与就会变得越来越好,我也会长期坚持维护,也欢迎大家的Issue和PR :>