
前一段时间刚到小米,由于一直以来都没从事过甲方安全,在熟悉工作的过程中慢慢有很多感触。于是就写下了这篇文章,其中的一些观点来自我个人的理解,如果有错误的话,麻烦联系我指出~
如果你在甲方从事安全行业,那我想DevSecOps是一个你不得不听说过的一个词语。从几年前甲方安全一直推行SDL开始,这几年DevSecOps又成了当前安全践行的主流方向。今天的文章我们就从DevSecOps开始,探讨在这个环节下的白盒究竟需要怎么样的形态。
什么是DevSecOps?
在聊DevSecOps之前,首先我们需要了解什么是SDL?
SDL全程安全开发生命周期,理论上讲是指一个帮助开发人员构建更安全的软件和解决安全合规要求的同时降低开发成本的软件开发过程。简单来讲,就是指将安全集成到软件开发的每一个阶段。在SDL中,安全的重点在于安全左移。它的原理基本上来源于安全的修复成本。
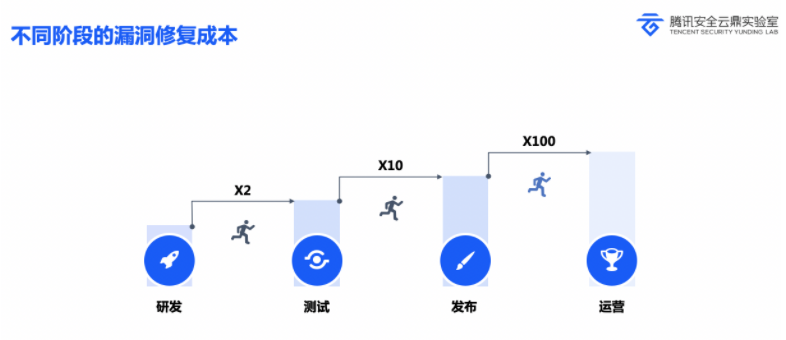
而DevSecOps之于SDL,有点儿像是CMMI和敏捷开发。大致上我们可以将前者认为是基于自动化的流程,将安全和运维集成在一起。将安全渗透到开发流程的每一个阶段。
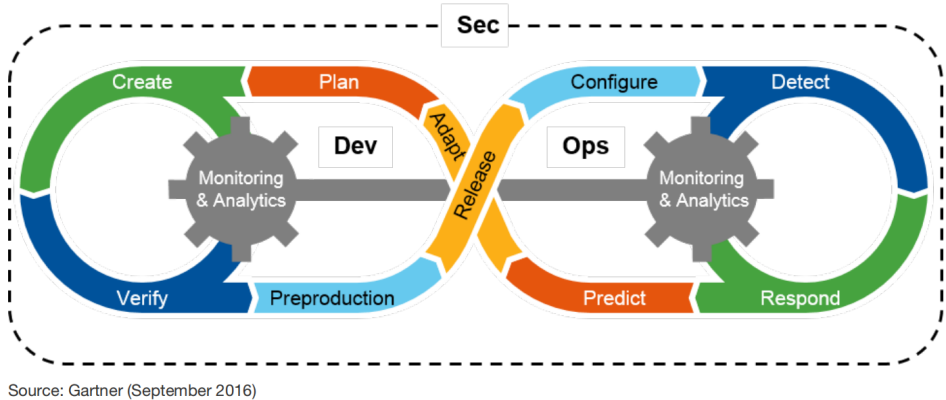
这是一张特别经典的DevSecOps流程图,在这个基础上,我们可以简单的认为,DevSecOps之于SDL最大的特点,就是自动化。
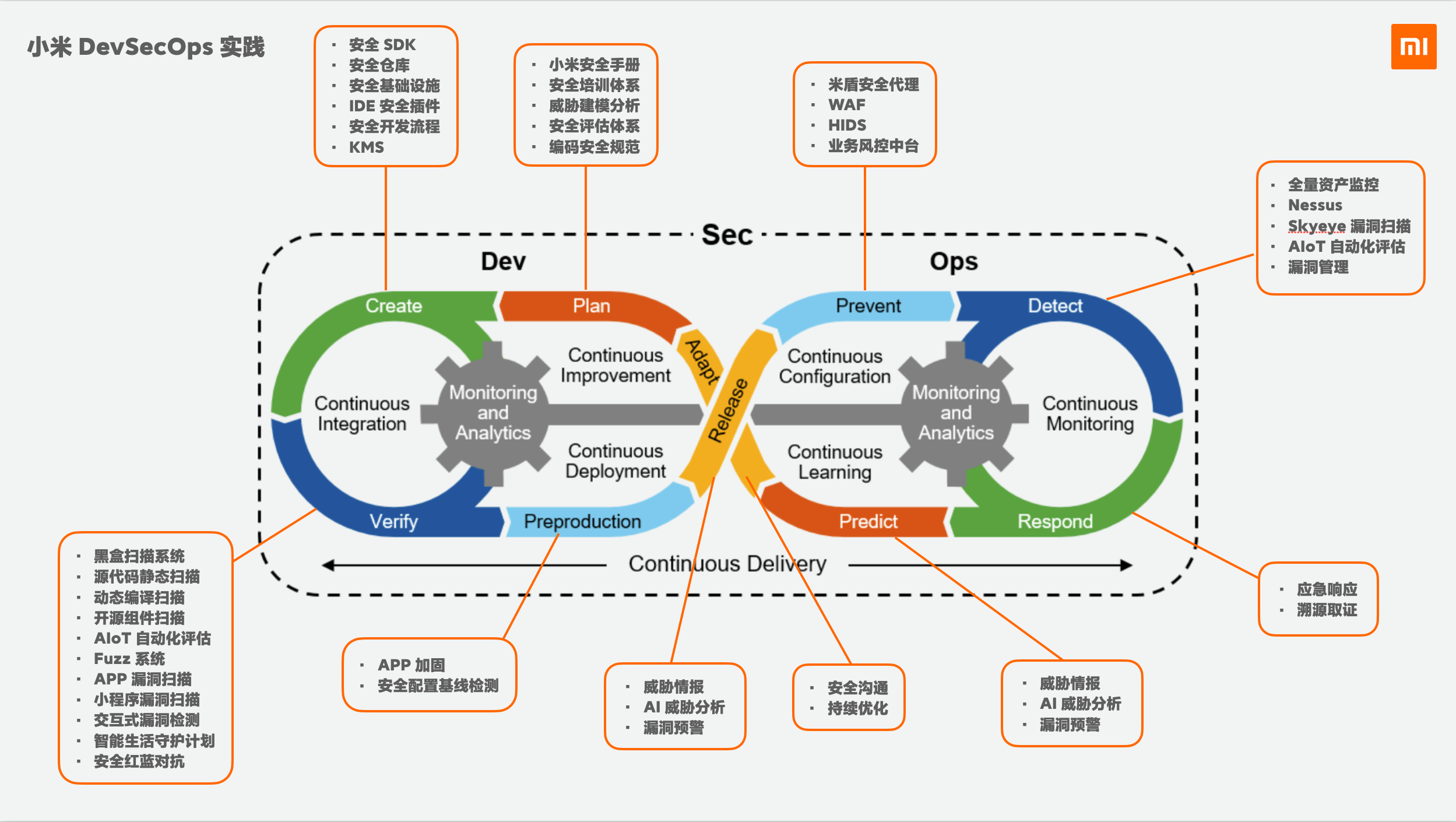
而涉及到自动化扫描的环节中,白盒和黑盒就是不可或缺的两个部分。而白盒部分一般主要有SAST/SCA 2个部分。
误报率/漏报率
一般来讲,我们会倾向于用误报率和漏洞两个概念来形容白盒和黑盒的扫描效果。
- 漏报率: 没有发现的漏洞/Bug
- 误报率:发现了错误的漏洞/Bug
在以前的文章中,我把市面上常见的安全工具大致分为高漏报低误报和高误报低漏报两类,在甲方的安全体系中,高漏报是无法接受的,所以大部分软件会采用高误报的解决方案,并逐步优化误报问题。
但在实际的甲方白盒实践过程中,我突然意识到,高误报带来的后果是不可逆反的。
安全工程师在面对大量的误报会造成“警报疲劳”,这个结果在某公司的一项内部调查中也可以发现,对于业务人员来说,如果误报超过20%,那么业务人员处理报警的积极性就会大大下降。而对于大部分白盒系统来说,这个数字会远远大于20,甚至超过50。而对于DevSecOps成熟流程来说,白盒的扫描结果应直接反馈到业务面前,一个安全人员都不愿意处理的结果又怎么谈得上业务开发会处理呢?这样一来,误报率对于白盒来讲就变成了重要的指标了。
相比误报率,漏报率对于白盒来讲却是一个更特殊的评价标准。在白盒中,我们大体上可以把漏报率定义为白盒检出漏洞/白盒应检出漏洞。而白盒应检出漏洞该怎么定义呢?
熟悉白盒的小伙伴一定会感同身受,就是白盒有许多力所不能及的范围,这里我举几个简单的例子:
- 与运行环境有关的安全问题(redis/tomcat漏洞)
- 业务逻辑漏洞(刷单,弱口令,越权)
- 多个系统联动导致的漏洞(由A控制B)
- 跨多个壁垒的漏洞(二次注入/二步XSS…)
- 没有代码的二进制导致的漏洞
这样的例子数不胜数,甚至我相信在安全流程推进比较成熟的公司中,甚至大比例的安全漏洞都是类似的问题。
在这个基础上,白盒检出漏洞 = 黑盒扫描漏洞 + SRC上报漏洞 - 白盒不可检出漏洞。
但是新的问题又出现了,在大部分的安全公司中,如何将这部分漏洞与白盒关联起来呢?常规意义上的安全测试/修复流程,能将一个漏洞直接关联到白盒层面吗,如果代码是第三方的又该怎么办?
在很多DevSecOps还在建设期间的公司,我相信漏报率都还是一个不可参考的数字,如何在流程上让白盒的参与度更直接,也是很多DevSecOps的一大挑战。
SCA - 组件安全扫描
SCA,Software Composition Analysis,软件成本分析,又叫组件安全扫描。SCA是整个白盒中,相对比较简单但是却效果比较好的部分。因为大部分公司的主流项目都是基于Java实现的,而围绕Java构建的开发生态普遍依赖第三方组件来完成开发,除了java以外,python、golang、nodejs都有大量的第三方组件,而这些大量的第三方组件可能会内置存在大量的漏洞,这就是SCA的起因,一般来讲市面上比较有名/常见的商用软件是BlackDuck、Checkmarx的CxSCA,国内也有做的比较好的比如默安sca等等,比较常见的就是github内置的组件扫描会定期提醒你升级你项目内的组件。

评价一个SCA是否好用的主要标准则是依赖的开源组件漏洞库是否够大够完整。这里我们不谈如何去爬取并构建数据库,而是回到SCA的技术本身上来聊聊。
- 第一阶段 - 漏洞数据库
最早期的SCA主要构成是漏洞数据库,一般来说,SCA开发者会通过爬虫去爬取CVE等各种漏洞公示网站,其中最重要的是如何将漏洞关联到组件以及版本中。
当有了一个量比较大且数据不断更新的漏洞数据库之后,我们就可以通过简单的比较漏洞印象版本来扫描组件漏洞。这个阶段的漏洞扫描往往效果非常好,只要数据有效性高,往往可以扫描到大量的安全问题。但是往往也会给业务人员带来一定的困扰。
- 第二阶段 - 函数级漏洞数据库
第二阶段的SCA就是为解决第一阶段的问题而诞生的。一般来讲,如果仅靠对比版本,业务开发人员会在短时间内收到大量的漏洞报送,其中甚至会包括大量没有修复版本、更新成本高的组件。而这时候大多数的业务反馈都会是“我写的那个地方会有安全问题?我该怎么办?”。
而这时候,如果可以将漏洞数据库至少细化到某个类/函数级,将会大大提高漏洞的有效性,也能为无法通过版本更新修复的漏洞提供解决方案。
- 第三阶段 - 代码片段级漏洞数据库
第三阶段的SCA,在第二阶段的基础上,将漏洞数据库进一步细化到代码片段级。一般意义上来说,这个级别的扫描主要解决的是大量项目中通过复制、二次开发的安全问题,而相应付出的代价可能是成几何级提高的数据库量以及扫描压力。
到这个阶段的投入是否值得可能还有待考量。
现在主流的SCA大部分还停留在第一阶段,部分商业的SCA开始逐步探索第二阶段、第三阶段,但真正将SCA完全自动化接入到DevSecOps流程中,我想还有很长的路要走(找10个“人工”智能审核 :>)。
基于第三方API的SCA或许也是不错的解决方案,KunLun-M采用https://deps.dev/作为SCA api.
SAST - 静态白盒审计
关于SAST的基础,可以参考《从0开始聊聊自动化静态代码审计工具》作为前置知识,这里我们不讨论关于技术原理本身。
在现代甲方的安全流程中,SAST一般会使用商业的CharkMarx、Fortify、Coverity、SonarQube作为主扫描引擎,也有在CodeQL的基础上二次开发,又或者类似Gitlab这类基于开源软件做集成扫描方案的,又或者是国产比较优秀的源伞、cobot等软件。
其中商业软件不但壁垒严重,而且大多数都价格高昂,不但需要花很高的价格购买软件,还需要对面业务人员配合做深度的商业支持,否则完全没办法使用。
而类似SonarQube等包括大量的开源安全扫描软件,主要做代码质量以及安全隐患的扫描,对于安全来说,不但存在大量的无意义数据,而且会导致“警报疲劳”。
而业界都比较认可的CodeQL解决方案,并没有降低多少白盒开发难度,反而引擎开发者和维护者存在天然的壁垒,后续如何发展可能还需要微软如何发力。
到目前为止,除了像阿里、华为、腾讯有能力从自研引擎做起以外,其他大多数甲方公司都仍然在花大价钱还是花大精力做开发中做选择。而我相信,对于大多数公司来说,采用自研白盒平台接开源引擎做覆盖,后期逐渐开发自研引擎,或许会是更现实的解决方案。
这里我也分享一些关于开源白盒的评价:
Findbugs/spotBugs:Java,主做代码质量扫描,可以作为插件引入到别的软件中,但安全扫描能力真的不强。
SonarQube: 主Java,其他语言仅支持简单的匹配,主做代码质量。
pmd/p3c:多语言,同理,也是主做代码质量扫描的,安全扫描质量比较差。
gosec: Golang,算是Golang扫描里比较有名的,但是内置的规则开发度太低,离开箱即用差的很远,可能需要深度二次开发才能使用。
joern:基于AST构造属性图,然后进一步分析。引擎说起来相当不错。但是无内置规则,需要对源码很了解之后做深度二次开发。
semgrep:算是综合程度比较高的多语言静态扫描工具。但是仅靠内置规则的话,没有太强的安全扫描能力,但是相比之下已经是效果很高了。
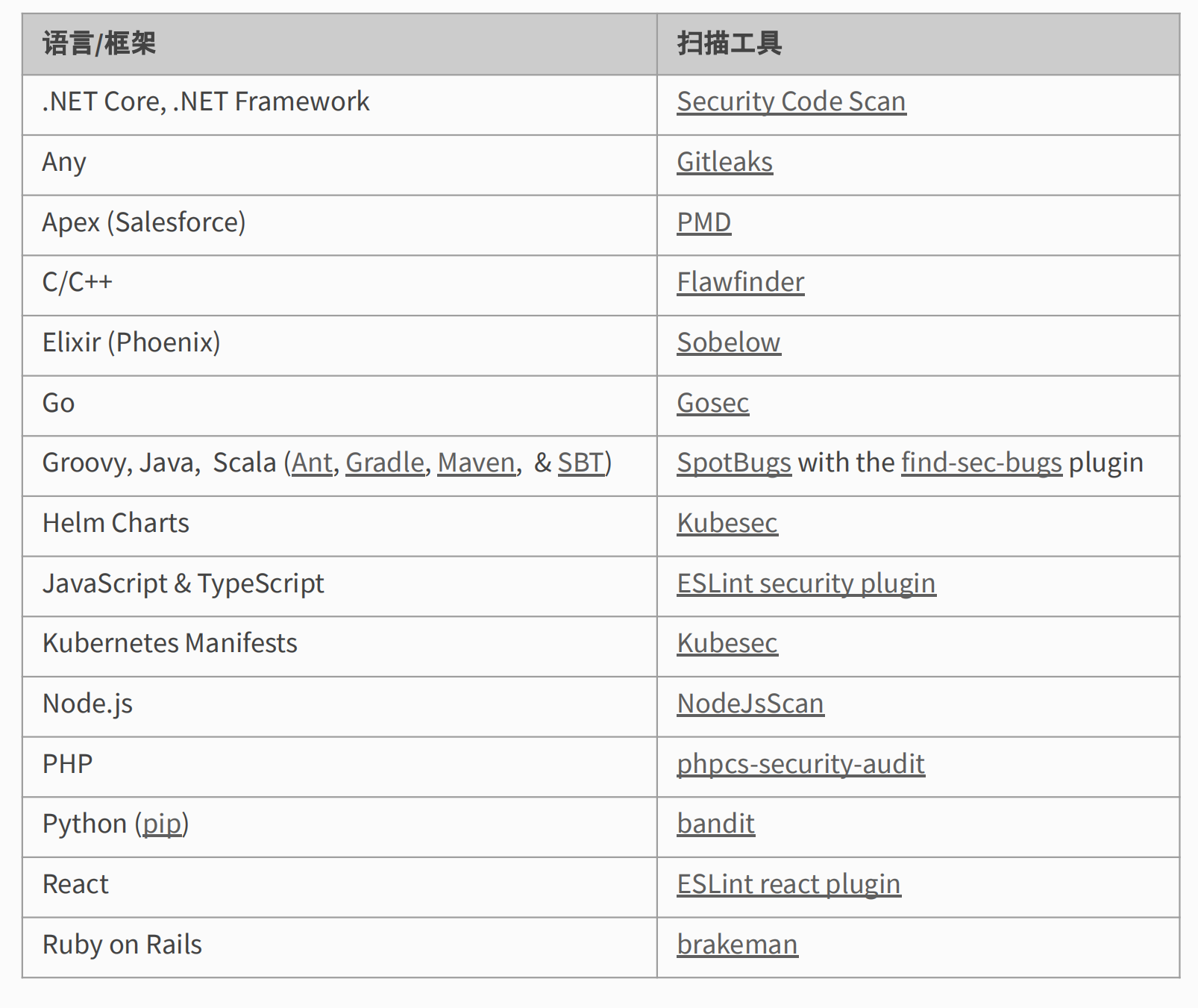
这是一张Gitlab内置的SAST引入表,其中大部分的开源工具检测能力都不强,但是他们都为自动化接入CI/CD流程做了专门的适配,这样帮助他们在许多引擎中脱颖而出,毕竟能用的才是最好的。
我们究竟需要怎样的白盒?
前面洋洋洒洒写了一大堆,到最后我们再回到最初的问题上来,DevSecOps究竟需要怎样的白盒?
我想这个答案至少是自动化、可用性高、与DevSecOps关联性强、扫描能力强。
自动化是DevSecOps的基础,一般来说,通过Ci/CD流程接入到自动化流程当中,是作为一个白盒软件最重要的基础,无论白盒扫描的结果是否影响流程,但这代表着白盒真正落地到安全流程当中,当然这个方式有很多,比如通过Gitlab的webhook或者ci,也比如从jenkins做定时任务。
可用性高则是指白盒工具在保证漏报率低的基础上,应该尽可能的降低误报率,一旦造成“警报疲劳”,即便是安全人员,也没办法及时处理成百上千的警报,时间久了白盒就成了摆设。
与DevSecOps关联性强则是把视角回到流程上来,如何黑盒漏洞修复关联到代码层面,如何将白盒漏洞关联到线上业务,如何把白盒以合适的方案接入到安全流程当中,这都是在实际场景下遇到的挑战。
扫描能力强则是回到技术基础,无论是从0开始做自研,还是做开源产品集成,又或者是购买商业产品做覆盖。扫描能力则是白盒的根,相比纯粹的技术能力而言,对于甲方来讲,更多的是可用性和投入做平衡,如何找到这个平衡点,可能又需要一段时间做探索。
KunLun-M
在开发KunLun-M的第一阶段,我把这个工具定位成了一个安全研究员的审计辅助工具,于是我把工具改造的重点放在了简化功能,以及优化底层的AST分析引擎。
但是在乙方做研究的时间里,我的很多理论收到了CodeQL等数据流分析的影响,我慢慢觉得在白盒的基础上寻找一个通用的全语言中介是白盒的终极形态,当时的很多想法包括CodeDB都是来自那个阶段,但是在实际开发之后,我逐渐开始意识到其实无论是否找到一个通用的中间截止,都改变不了白盒本身遇到的瓶颈,即便是像源伞那样找到一个中间语言,后续带来的效果也不甚实用。
于是我又开始了慢慢探索之路。到小米之后,我开始接受了公司内部白盒建设的工作,其中我也是真正从事DevSecOps相关的工作,其实我是很不喜欢玩概念的人,一直以来我都认可实用派,无论工具多好,概念多棒,只有能跑出结果能扫到漏洞,用起来好用的才能叫好的工具。于是在这个阶段我开始围绕KunLun-M去构建能够进一步使用的生态功能,我开始意识到只有cli模式会导致使用起来非常不便。所以KunLun-M这段时间都是在围绕server分离、web模式包括基于开源API的组件扫描,后面也打算逐渐支持直接对接ci等使用起来更直接的功能。在做好一个可以使用的工具之后,我们再慢慢从基础技术去提高扫描能力,毕竟,只有能用的工具才是好工具,对吧~