
SCA是什么?我想可能很多人都有这个问题。SCA的全称叫做Software Composition Analysis,有的朋友可能直接把他叫做软件成分分析,也可以叫他组件安全分析。现代的SCA大多数都是基于白盒的角度去做,也就是SAST中的一环,但是也有不少场景需求对二进制或者运行中软件做分析,当然这不是今天讨论的主要目标。这个东西最常见的地方就是github,github内置了一个简单的SCA扫描
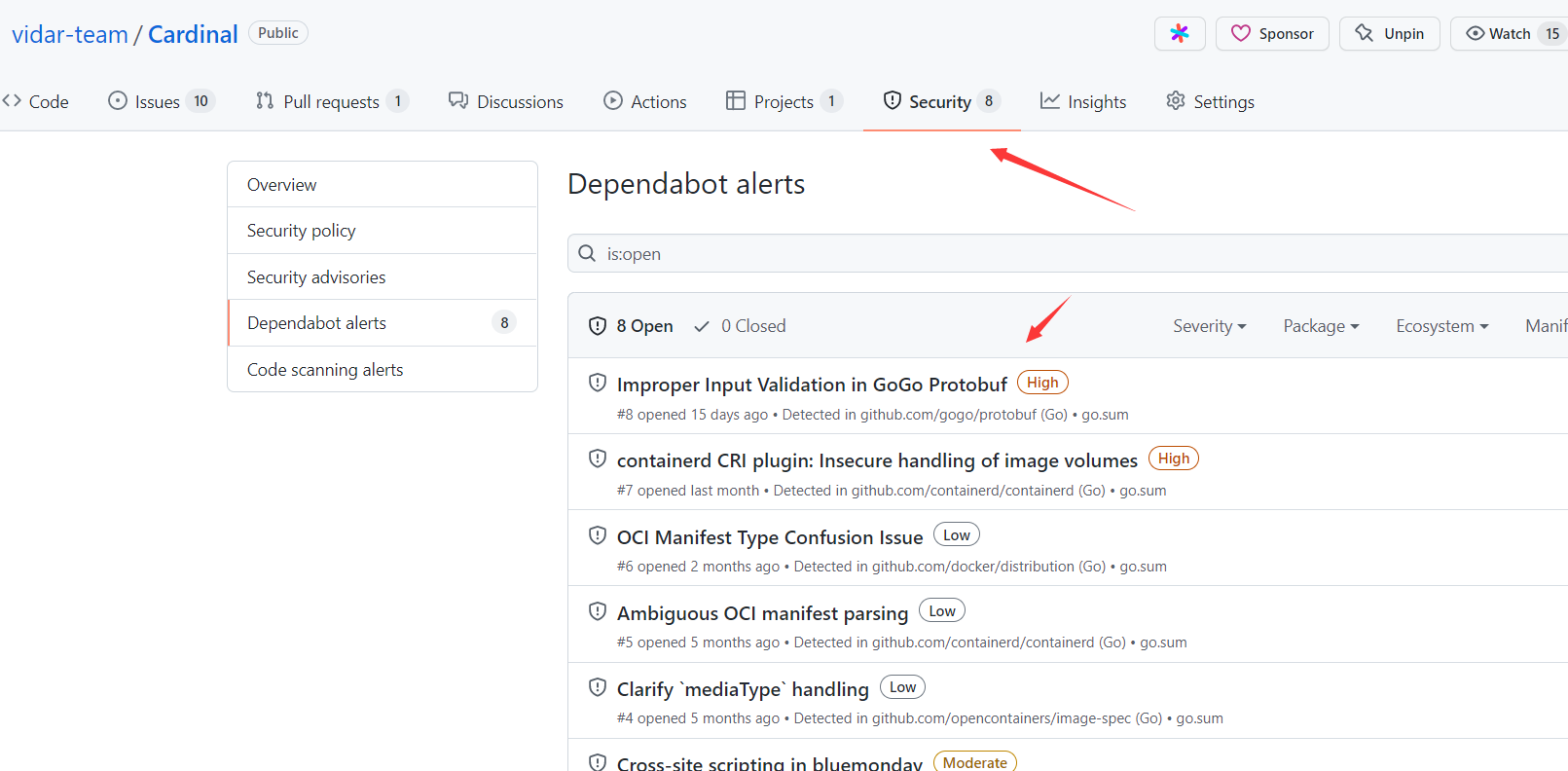
今天我们主要聊聊白盒角度的SCA,SCA这个东西听名字好像很复杂,但是实际上把它聊的简单一点儿可以拆开两部分,一个是组件数据,另一个是漏洞数据,我们分开聊聊这两个部分。
组件数据部分
其实组件数据对于现代的各种Web开发语言、框架啊没什么花头,每种语言都有自己的包管理工具。
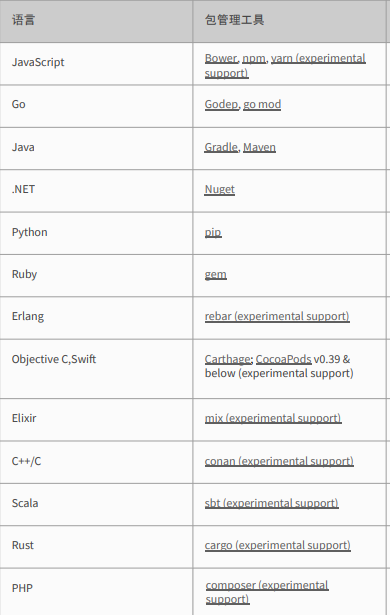
甚至里面的大多数语言依赖关系获取相当简单,比如php的composer.json,node的package.json,仅仅解析静态文件就可以获取非常完整的依赖关系。其中可以说问题最大的无非就是java的maven和gradle了,倒也不是说pom.xml获取不到相应的依赖,而是说java本身的组件体系完整而普适度高。这直接导致了,java当中频繁的使用了依赖引用链,这种引用关系往往可能存在2-3层以上,而这种依赖关系仅从静态的pom.xml中是没办法获取的。

这个问题在我之间做java的sca时,困扰了我相当一段长的时间,主要是我对SAST的很大一个理念和现在主流的SAST工具不同,我认为纯静态对于SAST来说是一个相当重要的点,包括白盒的工具,我也是在力求纯静态的扫描,这点和CodeQL、Sonarqube都不同,反而是Checkmarx和我的思路比较接近。
但是可惜的是,没有经过编译运行的java代码,一个是不会下载相应的组件包,你没办法通过解包jar的方式获取数据。另一个问题是,除了maven公开源的包,很多公司都会自建自己的artifactory,这样一来即便你本地已经存了数据量高达几十T的公开源依赖关系,你在公司中使用,也会出现大量的公司内部包,这样一来效果非常差。
所以,关于这个依赖获取的东西,现在普遍都是使用动态获取的方式,其中陌陌安全公开的就是这类工具的一个典型。
https://github.com/momosecurity/mosec-maven-plugin
可以说,除了hook maven以外,可能大多数办法都不如一句简简单单的**mvn** dependency:tree来的更直白。
其实抛开静态分析的角度,我们也可以把这个事情想的多元一点儿,前面的很多困扰都来自于静态的角度,我们总是在试图避免编译这个又浪费时间,又繁琐的步骤。但是换个角度去做,也许我们可以把脚本直接塞在CI/CD的流程中,甚至直接塞在Hids中,这种方案呢,在自动化程度比价高的公司非常好用,这本身也是DevSecOps中的一环。一个是避免代码库中的代码和实际运行的代码有差异(这个问题相当普遍),另一个是,这种方案本身对CI流程的干扰度也很低,因为编译本身就是流程的本身。
好了,现在我们有了组件数据这个东西,有很多人会好奇,他能干什么呢?这里我拿个最简单的例子来说,你们公司的Log4j2影响范围是怎么排查的呢?组件数据作为DevSecOps中的一环,是相对更底层的部分,你可以把它构建在白盒中,也可以把SCA相对独立,接入Hids以及更多来源的数据,这个数据本身就是意义,以后在聊到DevSecOps的时候,我可能会着重聊聊流程相关的东西,这里暂时先不提。
漏洞数据部分
在我们有了足够的组件数据之后,我们要开始和安全结合了。其实漏洞数据库可以说是SCA的核心技术了,这本身是一个数据驱动的玩意。其实相对安全问题本身来说,合规可能是大多数SCA的主要目标,在国外,很多软件上市之前,都需要通过安全合规扫描,这个安全合规扫描一般来说是黑盒的,但是你很难估计到底有什么样的问题。
而国外最有名的SCA就是BlackDuck,是新思做的一个东西,他本身其实安全的成分非常低,如果使用的朋友应该都知道,blackduck的扫描结果一个项目就有上千条,其中大多数都是那种毛用没有的问题。但是他最牛的地方就是,国外的很多检测机构使用的就是blackduck,所以很多厂商呢,也没有办法,为了通过安全合规扫描,就必须采购blackduck,为了这个简单的检测,blackduck的授权价往往有1年几百万,可以说是相当不讲理了。
我们说回技术本身,实际上在安全圈内,每年爆出来的组件漏洞不能说很多,关键是大部分都是特殊配置,实打实正儿八经能用的,都是那种要不就是默认配置,要不就是常用配置,像log4j2这种级别的漏洞我估计每5年能出一次都是很厉害了,上一次出这类漏洞已经是很多年前的fastjson了。所以现在很多公司的自建安全SCA中,漏洞数据库都是自己构建的,漏洞数据由安全运营中心负责,一个是来自于安全情报,另外一个是来自于SRC收集或者黑盒扫描后的排查,可能这个漏洞数据库常年也就维护20、30个漏洞,反而是DevSecOps中补足不足的好办法。
当然,你也许会问,会不会有那种有安全公司维护的API,可以提供有效的安全漏洞数据,目前我自己写的Kunlun-M中也是用了类似的方案,其中有两个API比较好用,一个是google的,另一个是osindex的,大家可以自己了解一下。
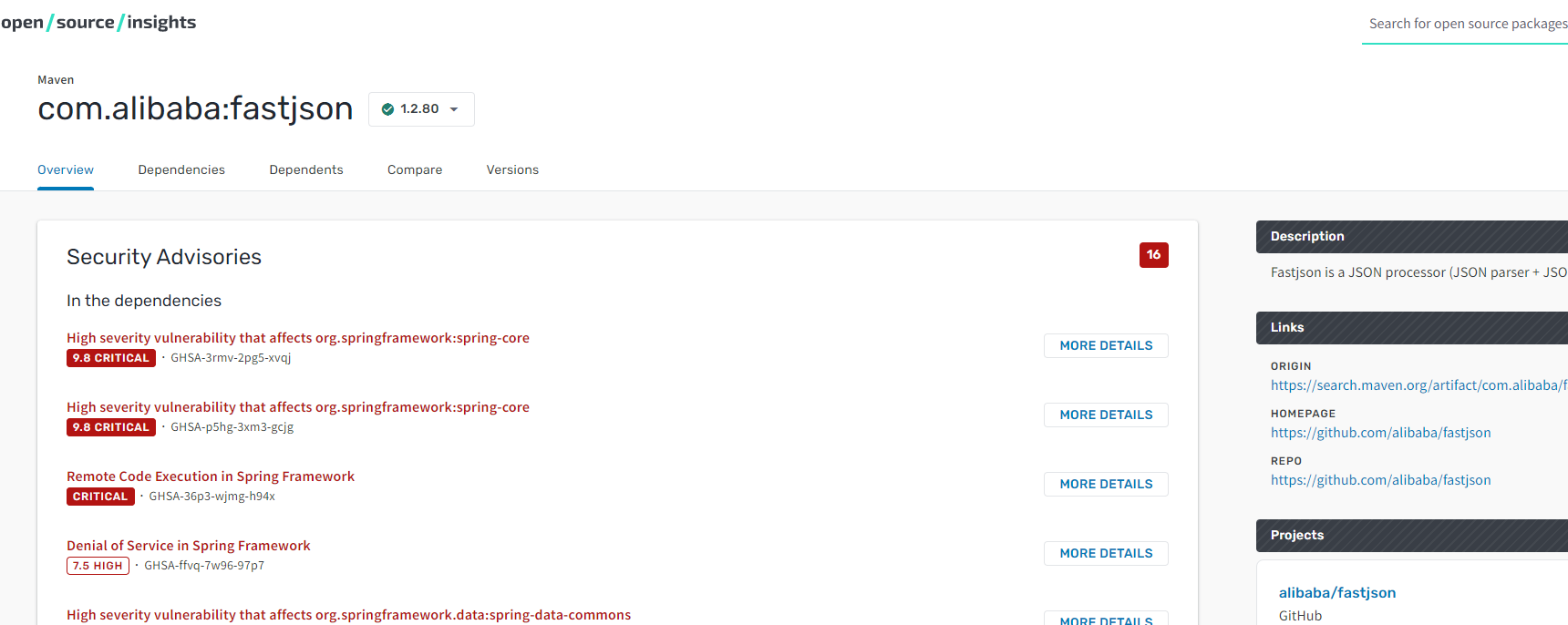
在这个网站中,你可以通过api查询提供对应的组件版本,他就会返回这个版本的所有漏洞列表。
在之前的<DevSecOps 究竟需要怎样的白盒?>这篇文章中,我把SCA分成了3个阶段。
- 第一阶段 - 漏洞数据库
最早期的SCA主要构成是漏洞数据库,一般来说,SCA开发者会通过爬虫去爬取CVE等各种漏洞公示网站,其中最重要的是如何将漏洞关联到组件以及版本中。
这个阶段就是我们现在的大多数SCA阶段,一个是漏洞数据没有特别好的办法精细化,另外一个是,乙方公司的工具大多都需要应对更多场景,所以漏洞数据库不免就会大而全,使用起来效果就会非常差了。
- 第二阶段 - 函数级漏洞数据库
第二阶段的SCA就是为解决第一阶段的问题而诞生的。一般来讲,如果仅靠对比版本,业务开发人员会在短时间内收到大量的漏洞报送,其中甚至会包括大量没有修复版本、更新成本高的组件。而这时候大多数的业务反馈都会是“我写的那个地方会有安全问题?我该怎么办?”。
而这时候,如果可以将漏洞数据库至少细化到某个类/函数级,将会大大提高漏洞的有效性,也能为无法通过版本更新修复的漏洞提供解决方案。
- 第三阶段 - 代码片段级漏洞数据库
第三阶段的SCA,在第二阶段的基础上,将漏洞数据库进一步细化到代码片段级。一般意义上来说,这个级别的扫描主要解决的是大量项目中通过复制、二次开发的安全问题,而相应付出的代价可能是成几何级提高的数据库量以及扫描压力。
到这个阶段的投入是否值得可能还有待考量。
现在主流的SCA大部分还停留在第一阶段,部分商业的SCA开始逐步探索第二阶段、第三阶段,但真正将SCA完全自动化接入到DevSecOps流程中,我想还有很长的路要走(找10个“人工”智能审核 :>)。
开源License合规
其实Sca当中,有一个很重要的功能,就是开源License合规扫描。这个东西主要也是用在国外,国内用的比较。这个东西同样也是安全合规扫描中的一部分,大概就是会扫描你的软件中使用的所有开源组件,并扫描你的软件是否符合你使用的开源软件License要求。
如果你使用了不符合你的软件的开源组件,那么你就无法扫描通过,同样的,这也是BlackDuck的一个主要功能。
前段时间在小米就遇到过类似的需求,很可惜的是,我发现国内貌似没有类似的软件,虽然说由于Blackduck的垄断导致这类软件没有市场,但是这个license扫描本质上也是一个数据驱动的玩意,相比黑鸭子昂贵的成本,其实还是有很多空间可以做的。
其实说来说去,SCA本质上还是一个数据驱动的东西,从安全研究的角度来看可能说也就是可以帮助你快速了解一份源代码,但是对于甲方来说,SCA却是白盒联动DevSecOps很重要的一部分,不仅仅是出于安全合规,帮助白盒获取更多的数据联动,也是非常重要的组成。