
前两篇文章主要讲了Joern相关技术的设计原理,以及CPG的实际表现
在研究Joern和Neo4j的过程中,我遇到了一个相当大的问题,就是由于我对OverflowDB包括scala和cypher语言都不熟。Joern和Neo4j分别支持这几种冷门语言,而相应的文档其实没有解决我的问题。
所以在继续研究Joern之前,先花时间简单记录一些Joern和Neo4j实用的语法和范例,给自己当个字典随时可以查阅。
Joern
节点获取
- cpg.method.name(‘xxx’)
- cpg.method(‘xxx’)
寻找对应名字的方法定义的位置
1 | joern> cpg.method.name("getRequestBody").l |
- cpg.call.name(‘xxx’)
- cpg.call(‘xxx’)
寻找对应方法/函数调用的位置
1 | joern> cpg.call("getRequestBody").take(1).l |
- cpg.annotation.name(“.*Mapping”)
- cpg.annotation(“.*Mapping”)
寻找对应名字注解的节点
1 | joern> cpg.annotation.name(".*Mapping").take(1).l |
在joern的节点你都可以非常简单的用点连接来获取对应节点连接的其他节点
1 | joern> cpg.annotation.name(".*Mapping").method.take(1).l |
除了常规的method,annotation,call这种以外,比较常见的节点类型还有
https://docs.joern.io/cpgql/node-type-steps/
- cpg.configFile:配置文件
- cpg.identifier:标识符
- cpg.imports:引用
- cpg.methodReturn:方法的返回节点
- cpg.parameter:参数
当然除了上面的这些节点以外,还有一些调用关系的通用节点
- cpg.method.name(“getRequestBody”).caller
返回节点列表对应节点的被调用节点,也就是父节点
- cpg.method.name(“getRequestBody”).callee
返回节点列表对应节点的调用节点,也就是子节点
- cpg.method.name(“getRequestBody”).callIn
返回节点列表对应父节点的所有节点
过滤器
凡是节点连接的都是作为结果传到下一级的,如果是想筛选符合条件的节点则需要用where或者属性过滤器,比如说
- cpg.method.name(“getRequestBody”).l
查询名字为getRequestBody,这个name就是属性过滤器,向下一级返回的是符合属性过滤器的method节点
- cpg.method.where(_.name(“getRequestBody”)).l
或者用where也行,where语句内容会作为筛选条件影响返回的method内容
- cpg.method.name.l
1 | joern> cpg.method.name.l |
如果不是使用()作为属性过滤器,那么返回内容就会直接变成name属性列表。
当然除了where以外,也支持很多种过滤器
where,whereNot:筛选返回为空或者非空的节点
- cpg.method.where(_.isExternal(false)).name.l
filter,filterNot:筛选返回为True或者False的节点
- cpg.method.filter(_.isExternal == false).name.l
and,or:多个过滤器之间的关系
返回结果处理
在处理结果返回的时候也有一些方式改变返回的内容。一般来说查询结果会是一个字典列表。
1 | joern> cpg.method.name("getRequestBody").l |
可以用map来改变返回的结构,这是一个类似于lambda的语法,会遍历列表的所有节点然后生成结果.
1 | joern> cpg.method.name("getRequestBody").map(n=>List(n.filename, n.lineNumber, n.fullName, n.code)).l |
除了map以外,另外还有两个实用的
- .clone,创建一个深复制,是在写比较复杂的脚本时候用到的
- .dedup,列表内容去重
- .sideEffect,按照格式要求执行但不改变原列表
重复获取
既然需要寻找两个节点之间的路径,那么就少不了重复,重复获取父级节点就是最简单的一种数据流分析。
- x.repeat(_.caller)(_.times(5))
重复获取caller共5次,如果找不到结果就会停止
- x.repeat(_.caller)(_.until(_.name(“foo”)))
重复调用 caller 查询,直到找到一个方法名为 foo 的方法,找不到就返回空。
- x.repeat(_.caller)(_.emit(_.isMethod).times(5))
emit的意思是会将查询的过程节点作为返回的列表中的一员。
上面这句语句就是指,重复5次获取当前节点的caller的节点属性,除此之外还会带上路径上所有满足isMethod的节点。
格式化
Joern对于返回结果提供了公式化的输出格式,而且如果不指定输出直接就没有返回
- toList,L,输出列表

- toJson,toJsonPretty,输出json或者格式化的json

- p,browse,输出可读性非常强的结果,如果是流会输出表格

- size,输出节点数量

- dump,dumpRaw,输出节点代码,只有节点才有这个属性

数据流分析
1 | def source = cpg.method.where(_.annotation.name(".*Mapping")).parameter |
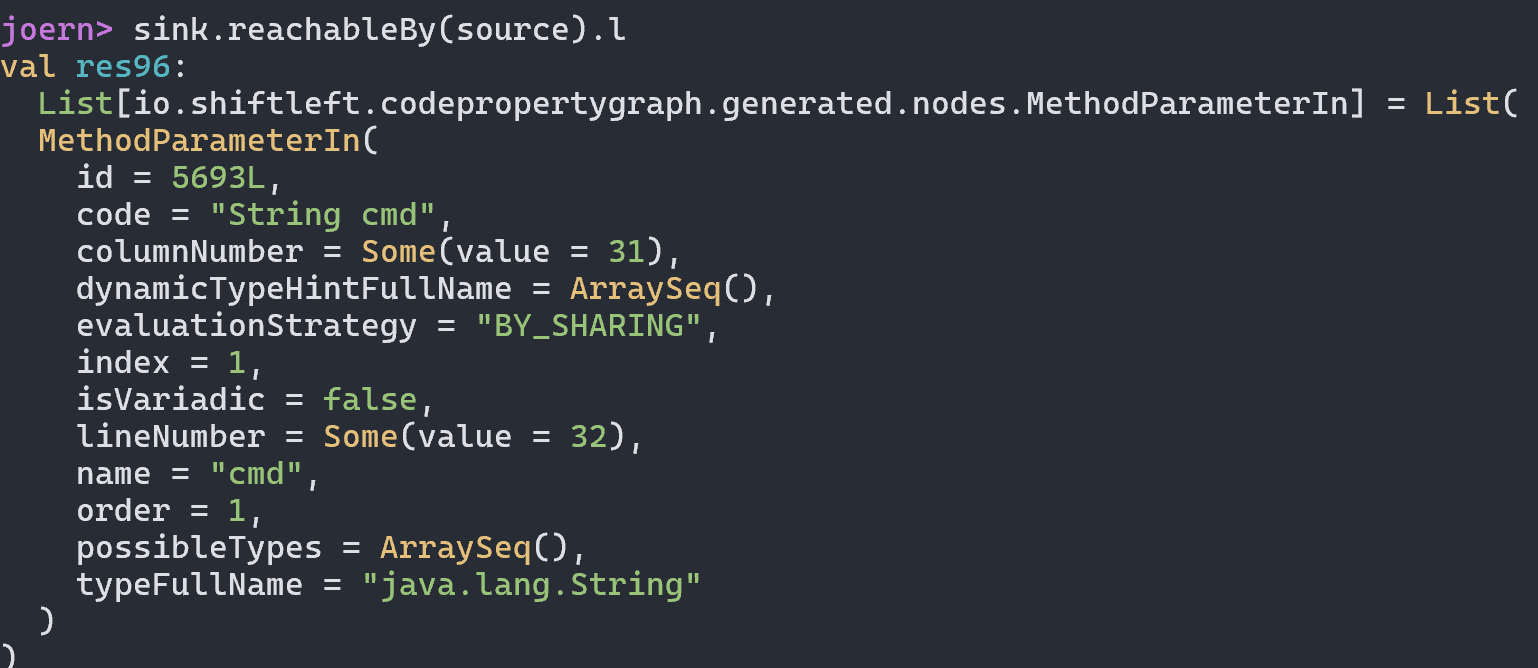
- reachableBy,是最简单的数据流分析函数,他返回的是从前面开始到后面,这个后面节点的位置。比如这里从sink开始查找,展示的就是source的位置
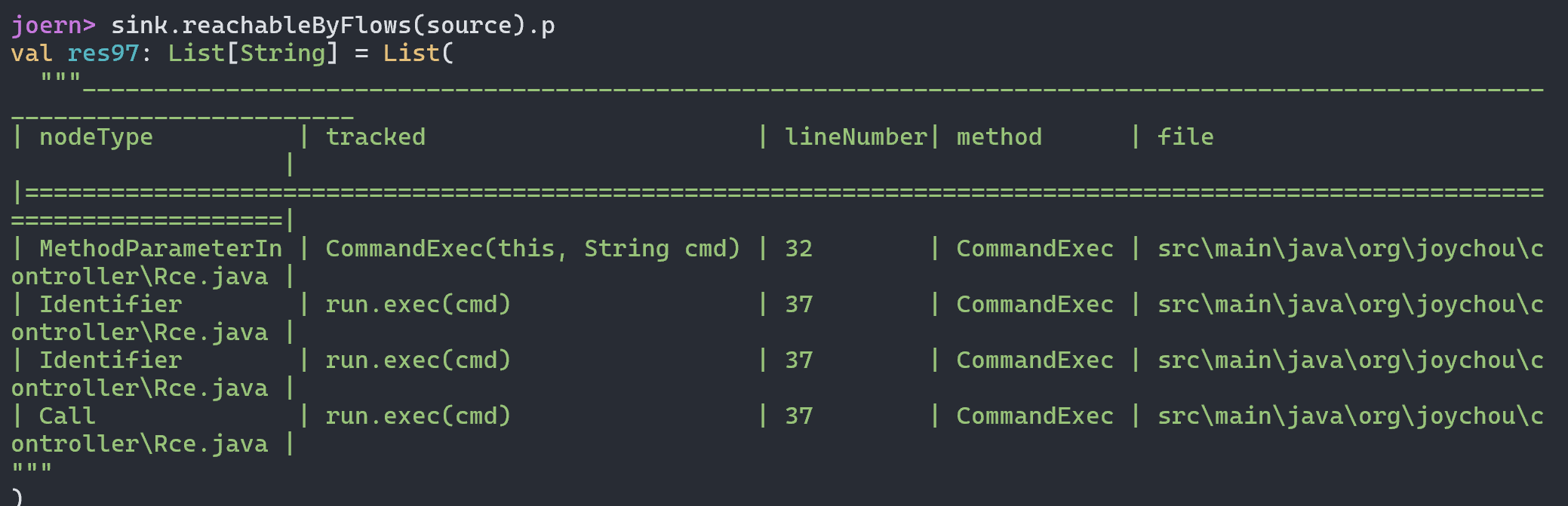
- reachableByFlows,展示两个节点之间的流,包括流上的每个节点
Neo4j
Neo4j的语法在我看来要比Joern的语法别扭多了,但有些问题其实在Neo4j会更容易得到答案,可视化的图结构在某些情况下会有非常明显的优势。
创建实体和关系
- 最简单的创建实体和关系(不带属性)
1 | create (n:Person)-[:LOVES]->(m:Dog) |
- 创建2个或多个属性的实体
1 | create (z:ziduan{name:"f_name",table:"dianlibiao"}) return count(*) |
- 创建带属性的实体和关系
1 | create (n:Person{name:"李四"})-[:FEAR{level:1}]->(t:Tiger{type:"东北虎"}) |
- 对实体间创建关系
1 | match (n:Person{name:""王五""}), (m:Person{name:"赵六"}) create (n)-[k:KNOW]->(m) return k |
delete 删除实体或关系
- 先用match查找已有实体、关系, 再用delete删除关系
1 | match (n:Person{name:"李四"})-[f:FEAR]->(t:Tiger) delete f |
- 删除所有节点中的边关系
1 | match(m)-[b:bian]-(n) delete b |
- match查询实体,delete删除实体
1 | match (n:Person{name:"李四"}) delete n |
- 同时删除实体和关系
1 | match(n) detach delete n |
- 删除所有节点
1 | match (n) delete n |
- 删除所有节点并级联删除关系
1 | match (n) detach delete n |
- 删除Loc标签的所有节点和关系
1 | MATCH (r:Loc) DETACH DELETE r |
match查询节点和关系
1 | match |
- n,代表Persion的别名
- :HAS_PHONE,代表前面Persion的关系
- (),括号里的都是实体
- [],中括号里的都是关系
- -,代表无方向的关系
- ->,代表有方向的关系
- 查询所有实体节点
1 | match(n) return n |
- 根据id查找实体
1 | match (t:Tiger) where id(t)=1837 return t |
- 多度关系查询
1 | match (n:Persion)-[:HAS_PHONE]->(p:Phone)-[:CALL]->(p1: Persion) where n.name=“姓名6” return n, p,p1 limit 10 |
- 利用关系查询, 不限定实体只限定关系的查询
1 | match p=()-[c: CALL]->() return p limit 10 |
- 根据实体属性匹配正则查询, 使用通配符,通配符前要加~
1 | match (n:USERS) where n.name=~'Jack.*' return n limit 10 |
- 包含查询 使用关键词contains
1 | match (n:USERS) where n.name= contains 'J' return n limit 10 |
- 附带属性多实体查询, 逗号隔开
1 | match (n:Person{name:"王五"}), (m:Person{name:"赵六"}) return n,m |
- 查询多种label节点,并进行过滤
1 | match(n) where n:标签1 or n:标签B return distinct n; |
- distinct * 关键字表示返回节点不重复
- 返回非某几类标签,注意使用 not and 关键字
1 | match(n) where not n:标签1 and not n:标签B return distinct n; |
set 修改实体标签或属性
- 实体增加标签
1 | match (t:Tiger) where id(t)=1837 set t:A return t |
本质上是给实体增加一个标签,一个实体可以有多个标签
- 给实体增加属性
1 | match (a:A) where id(t)=1837 set a.年龄=10 return a |
- 给关系增加属性
1 | match (n:Person)-[l:LOVE]->(:Person) set l.date="1990" return n, l |
- 给所有节点增加标签
1 | match(n) set n:table return n |
搜索路径
- 单条最短路径
1 | match (p1:Person{name:"姓名2"}),(p2:Person{name:"姓名10"}), p=shortestpath((p1)-[*..10]-(p2)) return p |
shortestpath()用于查询最短路径 [..10] 表示关系中*不超过10度关系**
- 多条最短路径
1 | match (p1:Person{name:"姓名2"}),(p2:Person{name:"姓名10"}), p=allshortestpaths((p1)-[*..10]-(p2)) return p |
关系查询
- merge 有关系则返回,没有则创建关系
1 | match (n:Person{name:"王五"}), (m:Person{name:"赵六"}) merge (n)-[l:LOVE]->(m) return l |
- optional match 可选择匹配,若匹配结果包含空,则用NULL占位
1 | OPTIONAL MATCH (n)-[r]->(m) RETURN m |
匹配结果集中如果有丢的部分,则会用null来补充
XXX with 字符串开头结尾匹配
- start with 匹配字符串的开头
1 | MATCH (n) |
- end with 匹配字符串的结尾
1 | MATCH (n) |
边对应的节点
- startNode(rel) 得到一条关系rel对应的起始节点
- endNode(rel) 得到一条关系rel对应的中止节点