
继续接着之前的内容来写,从通用大模型诞生到后续的几年里,除了大模型本身的能力一直在提升,使用大模型的方法论也在不停的变化。
这篇文章讲到的这些概念不是第一天诞生,我相信很多朋友也实打实的在使用这些方法论,那这篇文章让我们重新回顾一下这些概念,也伴随的感受一些,为什么这些方法论使得AI突然变得强力可靠?为什么在2025年年底I应用大量井喷?
什么是Skill?
在前两篇文章当中,我曾经提到过,AI有两个非常重要的时间节点,第一个是chatgpt的初诞生,它意味着AI与人类交流沟通的屏障解开了,我们可以通过对话和大模型沟通并让他理解我们的需求。
- chatgpt打通了人和AI的壁垒

在这个时间节点,大部分场景我们只能依赖prompt,提示词工程来一定程度的定向提高大模型的能力,虽然我觉得并没有什么卵用。

第二个关键的时间节点,gpt4在2023年初推出了Plugins功能,并且在2023年6月推出了Function Calling函数调用功能。
这意味着给给大脑接上了手和脚,大模型不再受限于自己提前训练的数据集,他可以主动调用其他工具收集信息,尤其是联网功能,大幅度提高了大模型的实用价值。
- ChatGPT Plugins的诞生
其实plugins和Function Calling功能,就是Skill的雏形。
Skill的本质其实就是,把某些特定的场景和解决方案收束成一个skill(技能),给予他一个触发条件,只有触发该条件才会读取这个Skill的内容并按照要求执行下去。

Skill的概念可以说是大模型应用非常核心的一部分,首先它拥有完全符合AI应用理念的特征,还能契合当前AI应用的实际场景。
- Skill本身独立于大模型外,不需要训练基础LLM,即插即用,还可以长期积累,符合AI学习成长的理念
- 只有触发才加载对应的skill,既节省不必要的上下文浪费,又可以在有需求的情况下及时引入必要的提示词和流程要求
一个非常有名的Skill叫做Skill Creator,调用它会辅助你构建一个Skill

现在主流的AI应用中,一般都对Skill做了专门的调度单元逻辑,甚至现在很多内置的功能都会通过skill的方式实现。
比如说claude code和codex,内置了十几种skill涉及大量和底层交互的场景,会在必要时触发
 )
)
现代的skill范式也越来越趋近于标准,从输入到执行流程,内置脚本,最后到输出的内容,都有相应的要求。
我个人觉得skill最大的问题是,可拓展性不够强,当你的skill少的时候,你描述触发的场景大体上比较稳定,但是如果skill太多,llm就很难判定触发了,经常会自己动手,某种程度上也符合人脑会混乱的事实。
比较理想的AI应用往往不会安装太多的Skill,是现在的一种解决方案。
什么是Agent?
如果说skill对于AI应用更多是理念上的进步,Agent和相应的概念更像是使用方法的进步。
在GPT-4诞生没几个月,在Plugins和Function Calling的基础上,社区爆发了大量的衍生项目,其中最有代表性的就是AutoGPT。
AutoGPT这类的应用引出了一个进阶的AI概念就是,我们可以把任务目标抽象成好多个步骤,由好多个独立的实体相互配合完成。
你可以理解为,每个独立的AI agent就是一个独立的人,原本我们是让一个人完成一个工作,这对这个人的能力就有非常高的要求。
现在我们用很多人分工去完成任务,可以把一个任务拆解成很多步骤,每个agent独立完成自己的事情。
有个形容我觉得比较贴切,Agent就是让AI从工具变成了员工。
Agent概念同样解决了LLM的几个大痛点
- 上下文不够长,即便现在达到上下文百万级别依旧困扰着AI,让一个Agent独立负责一个任务,可以最大程度的减少无效的上下文冗余,针对性更强的完成任务
- AI幻觉问题,减少无效信息干扰,Agent接收到独立的任务条件和目标,执行方向性会更强,互相也不会干扰
最早的多Agent应用,大多数都是让多个Agent一起做事情,那会儿非常经典的多AI辩论,看过不少。

让多Agent真正发光发热的破局点,就是工作流概念的诞生
什么是工作流?
工作流诞生的契机来的很快,在多Agent的理念出现之后,大家发现单纯让Agent独立完成任务的价值并不大,Agent本身容易失控,早期使用AI的普遍方案,都是让AI对同一个内容多次分析,最后取比例更好的那一个。
在23年底到24年,许多耳熟能详的AI平台诞生了,比如说Dify、Coze,他们都践行了Workflow的工作流理念。
工作流的核心理念是
将任务提前分成多个步骤,分别给每个步骤制定好输入、输出、需要完成的事情,最后再将任务的结果汇总并输入到下一个步骤。
在工作流的理念中,可以提前规划好步骤,也可以由AI规划划分步骤。
推进工作流,可以是类似于Dify这种程序推进Agent完成任务,也可以是由一个负责任Agent来推进任务,单个步骤的任务也可以独立启动多个Agent完成。
工作流诞生的价值一方面是完美利用多Agent的优势,独立Agent节省上下文,目标需求清晰互不干扰
另一方面是相比依赖Agent本身的执行结果,工作流的产出会更强势,这意味着工业化程度更高,那应用的结果效果也会更好。
像Claude Code现在就支持用工作流的方式驱动多Agent完成特定的任务,Codex可以通过Skill驱动工作流任务启动。
在历经了上面的3个关键节点之后,AI的基础方法论已经成型,但实际上距离现在真正的AI成熟化还有很长的距离,其中依旧有几个标志性的事件
慢思考AI的诞生
最早的AI模型都是基于快思考,看到问题直接输出答案,尤其是以GPT为代表,GPT-4模型最经典的问题就是偷懒,最经常的场景就是GPT-4会持续的问你问题。
在2024年底,慢思考模型的经典范例openai的o1模型和Deepseek R1模型,尤其是Deepseek,我个人感觉是从DS开始,我们经常使用的AI都会展示自己的思考过程。

慢思考AI诞生,对工作流本身造成了一定的降级,因为AI本身的思维能力足够强大,强流程的工作流某种程度上来说也成了有能力的AI的枷锁。这个话题我想在后面的文章中再讨论。
对于AI应用的意义来说,慢思考AI引领了后续AI大模型本身能力的提升方向,早期AI Agent你需要提出更明确的需求方式方法,现在的如果使用能力很强的Opus4.6这类大模型,你可以完全提出简单的需求,他会分析你的需求并结合实际场景完成任务,效果反而越来越好。
MCP是什么?
除了大模型本身的能力上升以外,关于方法论的变化也有,那就是MCP.
在2024年底,Anthropic提出了AI大模型的标准协议,就是MCP。其实单纯按照定位来说,MCP有点儿类似于Skill,但是MCP的针对性更强,MCP提出了一套双向通信的标准协议,允许AI大模型通过MCP协议无缝接入任何其他APP。
比较经典的通过mcp操作数据库,操作三方软件,很多公司为了拥抱MCP时代还推出了专门的MCP接口,这样AI在接入很多能力的时候就不用被迫应对原来的风控策略了。
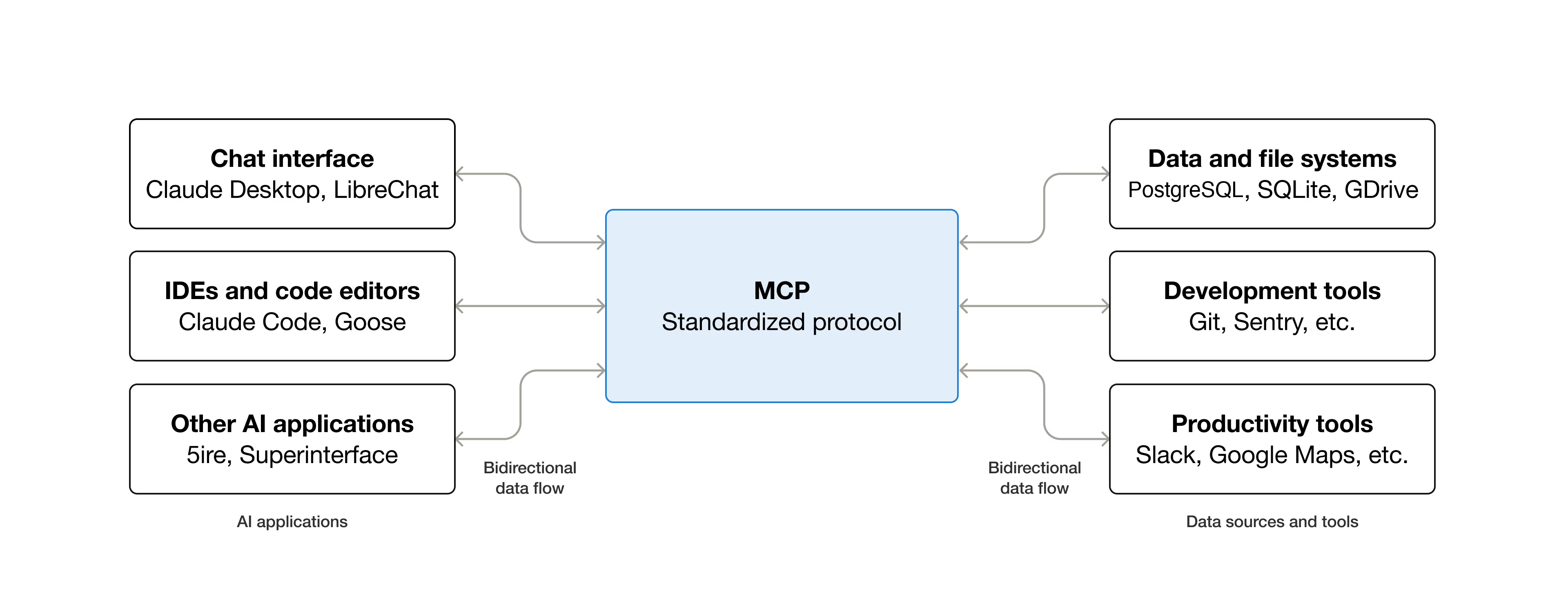
MCP的标准化对于AI Agent的长远发展有着非常特殊的意义,他倒逼厂家自己推出官方MCP,让Agent的触手延伸的更远。
GraphRAG 的出现
除了大模型的能力和AI方法论的演变,在24年诞生的GraphRAG则是在另一个维度上提升了AI能力的深度。
在GraphRAG之前,AI Agent应用的知识库,大部分是传统的RAG系统。
传统RAG的核心特质是,会把一篇文章切分成很多部分,然后把他们向量化,通过片段的向量相似度搜索相关的片段输入到AI,实现某种程度上的记忆,最大的问题是这种方案非常强烈的依赖切片的质量,或者这个问题的答案干脆就没有相似度,他的效果就会大大下降,这个问题曾经贯穿早期试图做AI搜索的许多方案,令人望而生却。
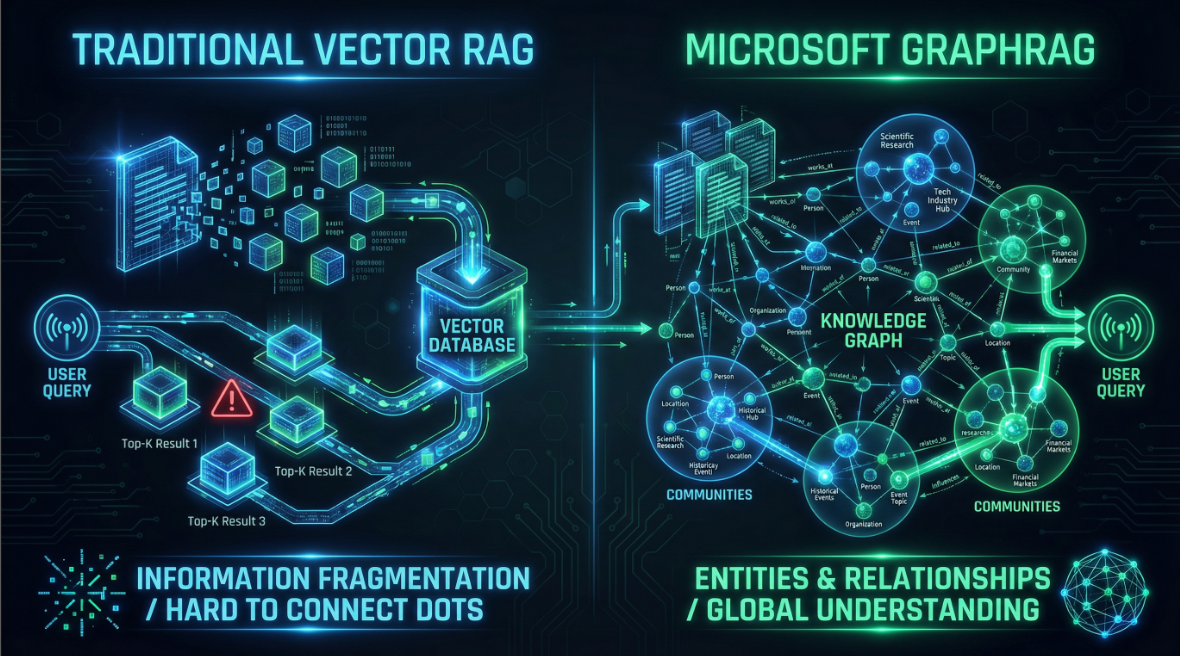
GraphRAG采用了图的基础结构,将目标转化为知识图谱,节点和关系作为核心,然后GraphRAG基于图算法把每一段信息内容总结为一个独立的社区,社区有大的总结,在子社区内又存在不同的节点和关系以供搜索。
这种基于图的逻辑结构在近几年的许多工业化产物上践行,他最大的优势就是在一个非常庞大的数据中可以快速的检索相关性,给数据降了维度。
GraphRAG理念的普及大幅度提升了现在AI大模型的长期记忆能力,而且这种深度记忆的理念在许多AI应用上都有更深层次的应用。结构化长期记忆让AI变的更具有成长性,也正是在这个基础上,后续衍生了更多关于培养AI的方法论,不再依赖模型本身的训练和微调,而是在使用方法的角度做培养。
Claude.md?
相比于大模型和应用原理上的进步,对于用户来说,方法论会有更直接的影响,比较有代表性的一个东西就是Claude.md,这个方法论被称之为“声明式智能体约束”。
很有趣的是这并不是Claude创造的概念,他最早诞生于家喻户晓的Cursor ,在AI代码编辑器Cursor 诞生之后,不可避免的衍生出了一个问题就是,如何让Cursor在每次编辑代码的时候,遵守开发者的基础要求和规范呢?
于是Cursor采用了.cursorrules的提示词文件,放在项目的根目录,Cursor每次执行任务都会先阅读这个文件作为高层级的记忆标准。
那又过了一段时间后Claude Code自然也沿用了这套方案,他们完成了分级的Claude.md。
你可以按照不同位置的Claude.md实现不同的场景定制化,比如说用户级,项目级,还可以多人维护开发要求。
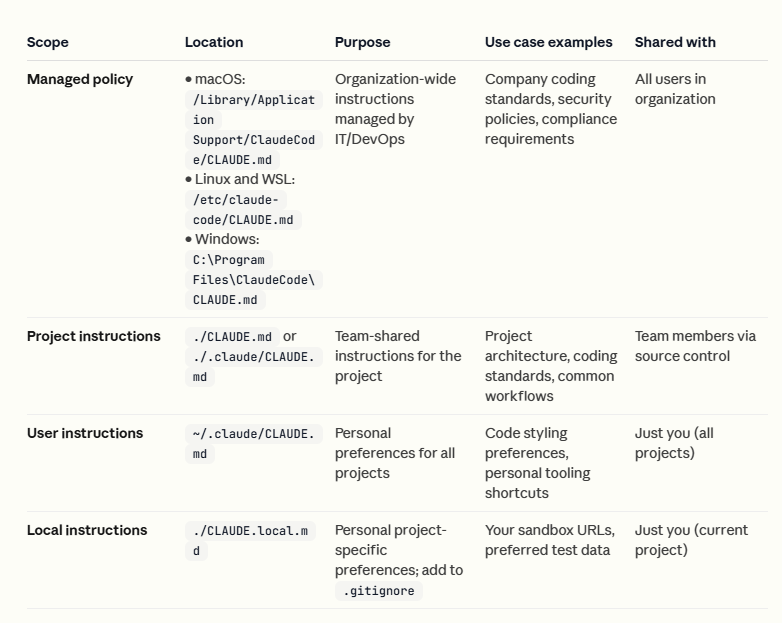
相比大模型本身的记忆,Claude.md这种提示词文件的主观性和强制性更强,还可以让AI自己总结并写入Claude.md。

这其实是一件非常有意思的事情:最初,顶级的 AI 科学家们(OpenAI、Anthropic)在拼命研究复杂的 JSON Schema、Function Calling 格式、复杂的 Agent 编排逻辑;但最后真正在一线写代码的程序员们发现,“在根目录扔一个 README 格式的 txt 文件给 AI 看” 才是最简单、最优雅、最符合直觉的解法。
为什么2025年AI应用井喷?
其实回顾以上的几个AI的方法论,最早的诞生于23年和GPT4一起诞生,最晚的基本上也不会脱离24年底,也就是说其实AI现在的主流方法论在24年底就已经形成了。
那为什么直到2025年年底,AI应用井喷式增长?
其实答案也很简单,就像移动互联网的爆发是3G/4G网络+APP生态+手机相关技术+时代发展集合一样,AI应用等来了大模型的能力上升(慢思考),等来了成本的暴跌(Deepseek蒸馏带来的启发),等来了AI操作的边界拓展(MCP),等来了成熟的方法论(Skill和多Agent),所以导致了今天的结果。